대규모 차원에서 공분산 행렬 추정과 PCA를 위한 스펙트럼 추정 통합 프레임워크
** 본 논문은 차원과 표본 크기가 비슷하거나 차원이 더 큰 상황에서, 샘플 공분산 행렬의 고유값을 비선형적으로 수축시켜 공분산 행렬을 추정하고 주성분 분석(PCA)을 수행하는 통합 방법을 제시한다. 핵심은 모집단 공분산 행렬의 스펙트럼(고유값 집합)을 일관적으로 추정하는 ‘QuEST’ 함수를 도입하고, 이를 이용해 최적의 오라클 비선형 수축 공식을 근사한다. 이론적 증명과 광범위한 시뮬레이션을 통해 제안 방법이 기존 기법보다 우수함을 확인…
저자: Olivier Ledoit, Michael Wolf
**
본 논문은 차원 \(p\)와 표본 크기 \(n\)이 같은 수준으로 커지는 ‘large‑dimensional asymptotics’ 상황에서, 공분산 행렬 추정과 주성분 분석(PCA)을 동시에 다루는 통합 프레임워크를 제시한다. 전통적인 고전적 방법은 \(p\)가 \(n\)에 비해 작을 때만 일관성을 보장하지만, 현대 데이터 분석에서는 \(p\)와 \(n\)이 비슷하거나 \(p>n\)인 경우가 빈번하다. 이러한 고차원 환경에서는 샘플 공분산 행렬 \(S_n\) 자체가 일관적이지 않으며, 고유값·고유벡터 역시 왜곡된다.
### 1. 기본 가정 및 이론적 배경
- **Assumption (A1‑A4)**: 모집단 공분산 행렬 \(\Sigma_n\)는 양정치정(positive‑definite)이며, 표본 행렬 \(X_n\)는 i.i.d. 평균 0, 분산 1, 4차 모멘트 유한인 실수값을 갖는다.
- **비율 \(c = \lim p/n\)** 가 0이 아니고 1이 아닌 유한 양수로 수렴한다.
- Marčenko–Pastur 법칙을 이용해 샘플 고유값 분포 \(F_n\)가 제한 분포 \(F\)로 수렴함을 이용한다. Stieltjes 변환 \(m_F(z)\)와 제한 스펙트럼 분포 \(H\) 사이의 관계식(2.5‑2.10)를 기반으로 한다.
### 2. QuEST 함수와 개별 고유값 수렴
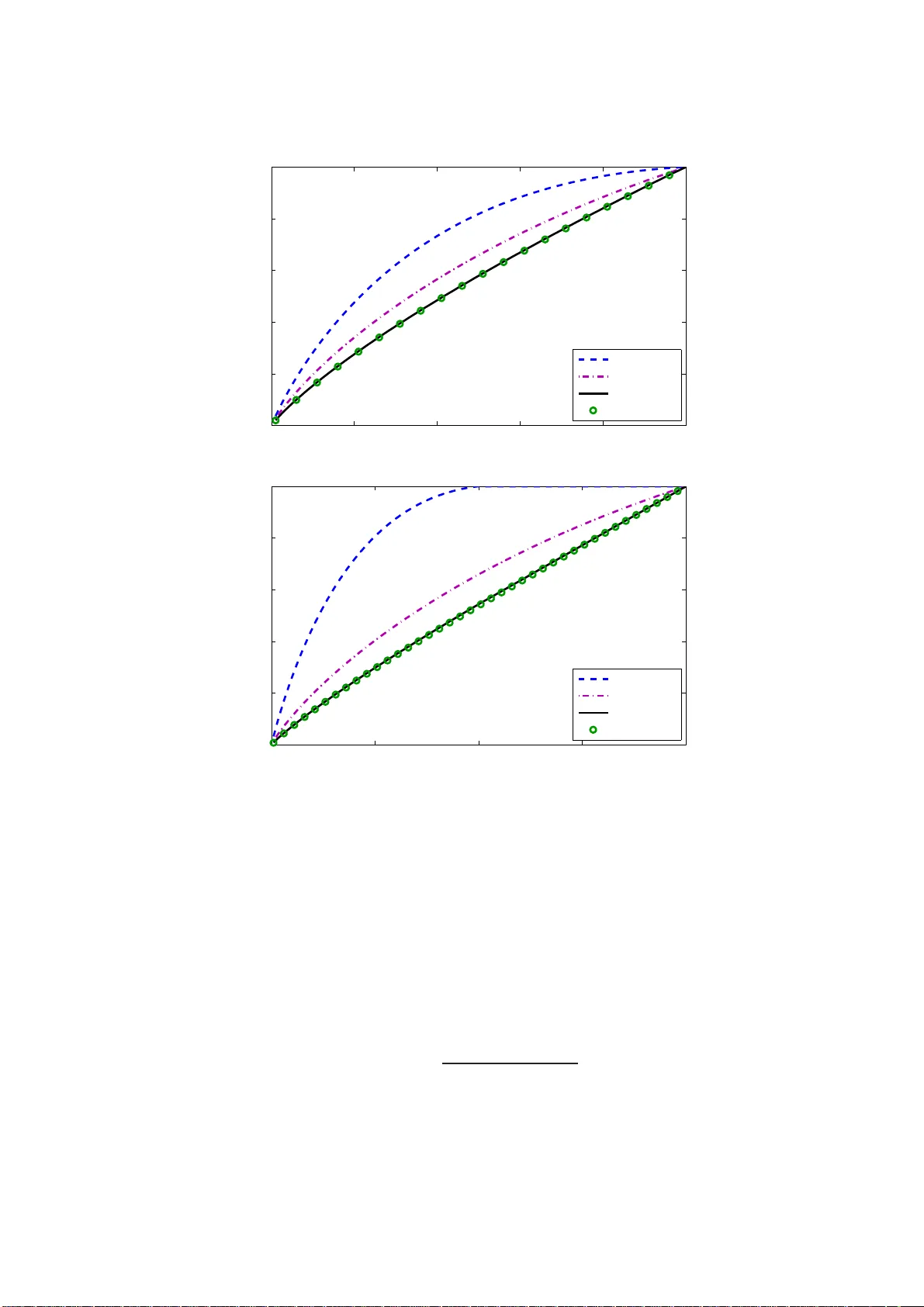
저자들은 **QuEST(Quantized Eigenvalues Sampling Transform)** 라는 새로운 함수 \(Q_{n,p}\)를 정의한다. 이는 모집단 고유값 벡터 \(\tau = (\tau_1,\dots,\tau_p)\)를 입력받아, 이론적으로 대응되는 샘플 고유값 \(\lambda = (\lambda_1,\dots,\lambda_p)\)의 ‘양자화된’ 버전을 출력한다. 구체적으로는 Stieltjes 변환을 이용해 (2.13‑2.17) 식을 풀어 각 \(\tau_i\)에 대응하는 \(\lambda_i\)를 계산한다.
**정리 2.1**은 \(\frac{1}{p}\sum_{i=1}^p (\lambda_i - q_i(\tau))^2 \xrightarrow{a.s.} 0\)임을 증명한다. 이는 샘플 고유값이 개별적으로 QuEST 함수에 의해 결정된 값에 거의 일치한다는 의미이며, 기존 평균적 수렴 결과보다 훨씬 강력한 ‘점별(pointwise) 일관성’을 제공한다.
### 3. 비선형 수축과 공분산 행렬 추정
고유값을 정확히 복원한 뒤, 최적의 비선형 수축 함수를 적용한다. 오라클 비선형 수축 공식은 Frobenius 노름 기준으로 최소 평균 제곱 오차를 달성하는 형태이며, 모집단 고유값 \(\tau_i\)에 의존한다. 하지만 \(\tau_i\)는 관측되지 않으므로, QuEST를 통해 추정된 \(\hat\tau_i = q_i^{-1}(\lambda_i)\)를 사용한다. 이렇게 얻은 수축된 고유값 \(\hat d_i\)와 원래 샘플 고유벡터 \(u_i\)를 결합해
\
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기