자연스러운 소스코드 생성을 위한 구조적 생성 모델
본 논문은 인간이 작성하고 이해하는 자연스러운 소스코드(NSC)를 모델링하기 위해, 추상 구문 트리(AST)를 기반으로 한 계층적·순차적 구조와 컴파일러 정보를 결합한 로그-바이리니어 트리-트래버설(LTT) 모델을 제안한다. 변수 스코핑, 타입 정보 등을 트래버설 변수에 포함시켜 컨텍스트 의존성을 강화하고, 효율적인 학습 및 샘플링 알고리즘을 제시한다. 실험 결과, 기존 n‑gram·PCFG 기반 베이스라인보다 로그우도와 테스트 프로그램 생성 …
저자: Chris J. Maddison, Daniel Tarlow
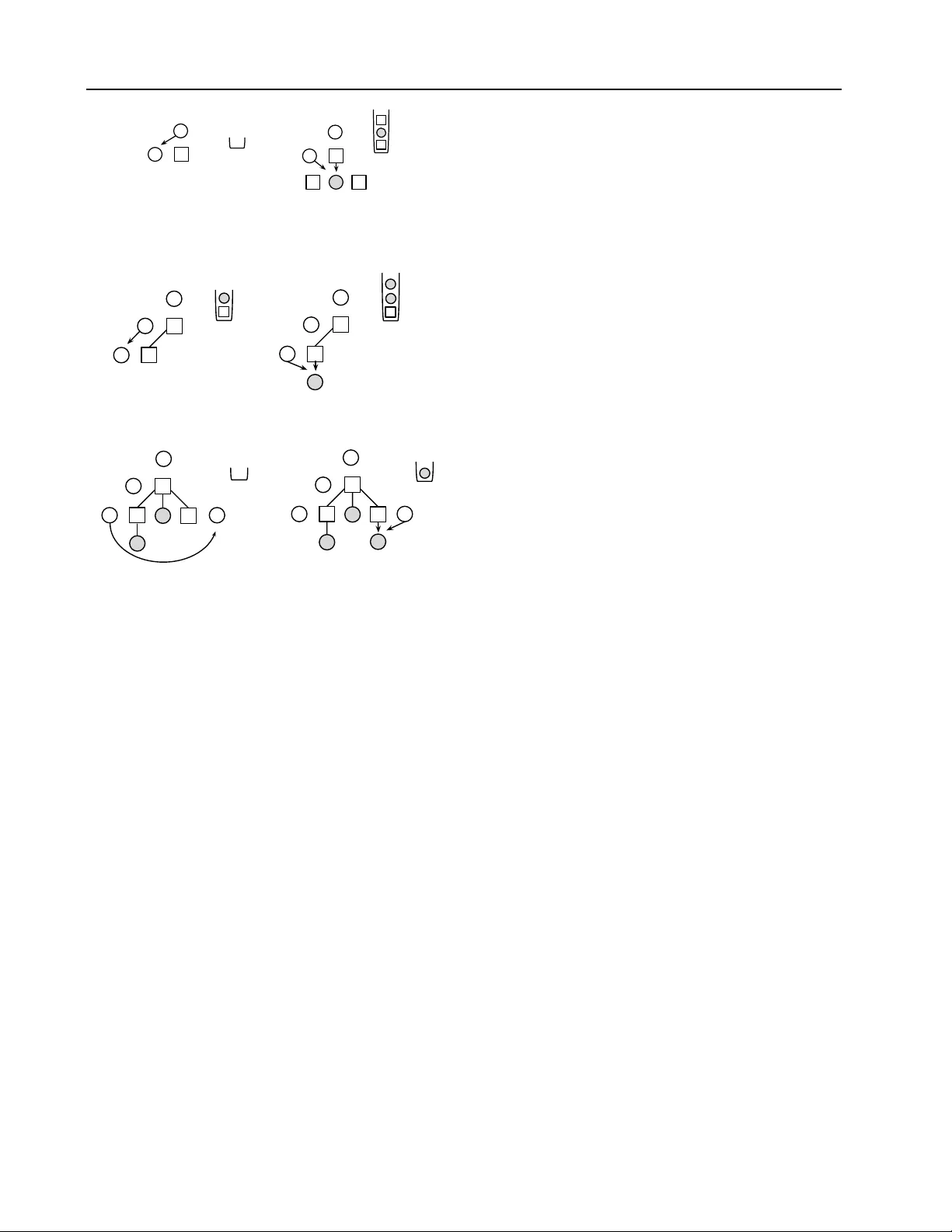
논문은 인간이 작성하고 이해하는 자연스러운 소스코드(Natural Source Code, NSC)를 대상으로, 기존의 평면 시퀀스 모델이 갖는 한계를 극복하고자 새로운 구조적 생성 모델을 제안한다. 먼저 서론에서는 코드 자동 완성, 버그 탐지, API 사용 패턴 마이닝 등 다양한 소프트웨어 엔지니어링 과제에 머신러닝을 적용하려는 동기를 설명하고, 특히 코드가 갖는 계층적 구조와 컴파일러 수준의 제약(스코프, 타입, 선언‑사용 관계 등)이 모델링에 반드시 포함돼야 함을 강조한다.
2장에서는 소스코드 모델링에 필요한 기본 요구사항을 정리한다. 첫째, 토큰을 단순 시퀀스로 보는 것이 아니라 추상 구문 트리(AST)를 기본 표현으로 채택한다. AST는 리프 토큰과 내부 노드(문, 식, 블록 등)로 구성되며, 트리 구조만으로도 변수 스코프와 타입 정보를 추론할 수 있다. 둘째, PCFG와 같은 전통적 확률 문법은 트리 생성에 적합하지만, 자식 튜플을 독립적으로 샘플링하는 가정 때문에 식별자 이름이나 타입 일관성 같은 컨텍스트 의존성을 포착하지 못한다. 이를 보완하기 위해 저자들은 ‘트래버설 변수’ hᵢ를 도입한다. hᵢ는 현재까지 생성된 부분 트리와 스코프 정보를 요약한 벡터이며, 노드 nᵢ가 팝될 때마다 업데이트된다.
3장에서는 Log‑bilinear Tree‑Traversal(LTT) 모델을 구체화한다. LTT는 깊이 우선 탐색(DFS) 기반의 스택 알고리즘을 사용해 트리를 순차적으로 생성한다. 각 단계에서 (nᵢ, hᵢ) 쌍을 입력으로 받아 자식 튜플 Cᵢ의 분포 p(Cᵢ|nᵢ,hᵢ)를 로그‑바이리니어 형태로 파라미터화한다. 구체적으로, R_con(nᵢ,hᵢ)=W₀R_{nᵢ}+∑_j W_j R_{hᵢⱼ} 로 컨텍스트 벡터를 구성하고, R_ch(Cᵢ)와 b_ch(Cᵢ)와의 내적을 통해 에너지 E를 계산한다. p(Cᵢ|nᵢ,hᵢ)=exp(−E)/Z 로 정규화한다. 여기서 Z는 해당 부모 노드 타입 nᵢ에 대해 학습 데이터에 나타난 모든 자식 튜플 집합 위에서 계산된다. 이 설계는 파라미터 수가 hᵢ 차원에 선형적으로 증가하도록 하여, 고차원 컨텍스트를 효율적으로 학습할 수 있게 한다.
4장에서는 LTT의 확장을 논한다. 트래버설 변수는 ‘확정적(deterministic)’과 ‘잠재적(latent)’으로 구분된다. 확정적 변수는 현재 부분 트리에서 직접 계산 가능한 스코프 집합, 조상 노드 타입, 최근 n개의 토큰 등이며, 이를 통해 p(hᵢ|hᵢ₋₁)를 p(hᵢ|전체 히스토리) 로 일반화한다. 잠재적 변수는 학습 과정에서 추정해야 하는 은닉 상태를 의미한다. 특히 변수 스코핑을 구현하기 위해, 현재 스코프에 존재하는 변수들의 타입·이름 정보를 hᵢ에 포함시키고, 자식 튜플 생성 시 스코프 내 변수만 선택하도록 제약을 부여한다. 이렇게 하면 ‘i’, ‘j’와 같은 전형적인 루프 변수 명명 규칙을 자연스럽게 학습하고, 선언되지 않은 변수 사용을 방지한다. 또한 노드에 풍부한 타입 어노테이션을 추가함으로써, 타입 일관성을 보장하는 더 정교한 모델링이 가능해진다.
5장에서는 학습 알고리즘을 제시한다. 전체 로그우도 L=∑_data log p(tree) 를 최대화하기 위해, 스택 기반 생성 과정과 트래버설 변수 업데이트를 포함한 전체 그래프를 자동 미분 프레임워크에 매핑한다. 파라미터는 Adam 옵티마이저로 업데이트되며, 미니배치 학습이 가능하도록 트리 구조를 배치화한다. 또한, 트래버설 변수의 확정적 부분은 직접 계산되므로 추론 비용이 크게 증가하지 않는다.
실험(7장)에서는 C# 코드를 대상으로 Roslyn 컴파일러 API를 이용해 AST와 스코프 정보를 추출하고, 약 1천만 라인의 코드베이스를 학습 데이터로 사용한다. 비교 모델로는 n‑gram, 전통적 PCFG, 그리고 로그‑바이리니어 트리 모델(구조 없이) 등을 포함한다. 평가 지표는 테스트 셋에 대한 평균 로그우도, 생성된 코드의 컴파일 성공률, 그리고 인간 평가자에 의한 코드 자연스러움 점수이다. LTT는 모든 지표에서 현저히 높은 성능을 보였으며, 특히 변수 스코프와 타입 일관성을 유지한 코드 샘플을 생성함으로써 기존 모델이 생성한 무의미한 식별자 사용을 크게 감소시켰다. Fig. 1은 PCFG와 LTT가 생성한 for‑loop 샘플을 비교하며, LTT가 더 현실적인 변수 명명과 스코프 사용을 보여준다.
결론에서는 LTT가 코드 자동 완성, 버그 탐지, 프로그램 합성 등 다양한 응용 분야에 확률적 사전 지식으로 활용될 수 있음을 강조하고, 향후 연구 방향으로 더 복잡한 언어 특성(예: 제네릭, 람다식)과 다중 파일·프로젝트 수준의 스코프 모델링을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기