통신 최소화 병렬 MCMC 정확도와 확장성을 동시에
데이터를 여러 머신에 임의로 분할하고, 각 머신에서 기존 MCMC(예: Gibbs, Metropolis‑Hastings)를 독립적으로 실행한다. 이후 각 서브포스터리어 샘플을 결합해 전체 데이터의 포스터리어에서 정확히(점근적으로) 샘플링한다. 통신은 최종 결합 단계에서만 발생해 병렬화 효율이 크게 향상된다.
저자: Willie Neiswanger, Chong Wang, Eric Xing
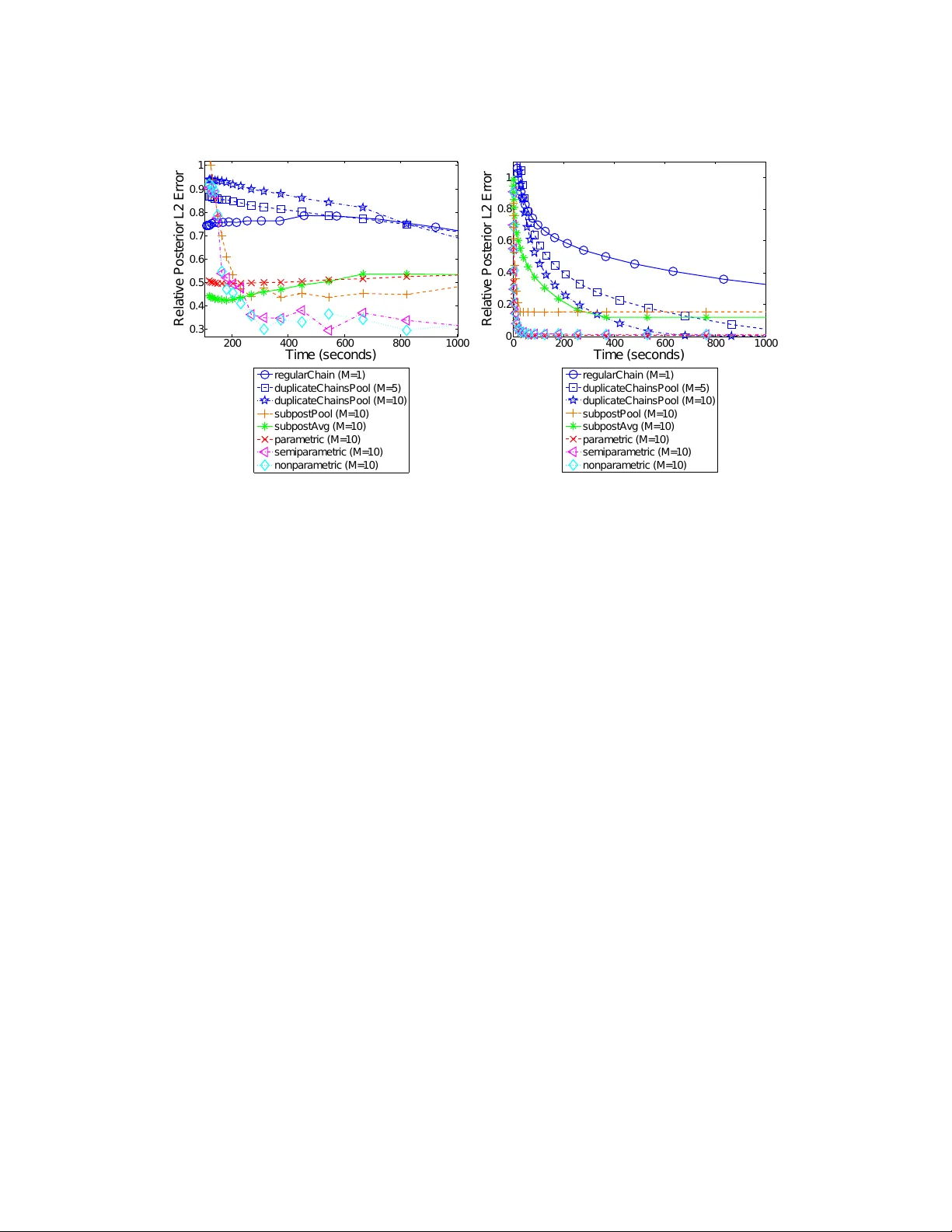
본 논문은 대규모 베이지안 추론에서 병렬화와 정확성을 동시에 달성하기 위한 **Embarrassingly Parallel MCMC**(EPMCMC) 알고리즘을 제안한다. 기존 MCMC는 전체 데이터에 대해 \(O(N)\) 연산을 필요로 하며, 특히 데이터가 여러 머신에 분산돼 있을 경우 매 이터레이션마다 통신이 발생해 병목이 된다. 저자들은 이 문제를 해결하기 위해 다음과 같은 두 단계 프로세스를 설계한다.
**1. 데이터 분할 및 서브포스터리어 샘플링**
전체 데이터 집합 \(x_{1:N}\) 을 \(M\) 개의 서브셋 \(x^{(1)},\dots,x^{(M)}\) 으로 임의 분할한다. 각 서브셋에 대해 **서브포스터리어** \(p_m(\theta)\propto p(\theta)\,p(x^{(m)}\mid\theta)^{1/M}\) 를 정의한다. 여기서 사전분포 \(p(\theta)\)는 모든 서브셋에 동일하게 적용되며, \(1/M\) 스케일링은 사전이 중복 적용되는 것을 방지한다. 각 머신은 기존의 MCMC 알고리즘(예: Gibbs, Metropolis‑Hastings)을 그대로 사용해 \(p_m(\theta)\) 에서 독립적인 체인을 실행한다. 이 단계에서는 머신 간 통신이 전혀 필요하지 않으며, 따라서 **완전한 임베러싱(parallel) 실행**이 가능하다.
**2. 서브포스터리어 샘플 결합**
각 머신에서 얻은 \(T\) 개의 샘플 \(\{\theta^{(m)}_t\}_{t=1}^T\) 을 이용해 전체 포스터리어 \(p(\theta\mid x_{1:N})\) 와 비례하는 **밀도 곱** \(p_1(\theta)\cdots p_M(\theta)\) 을 추정한다. 저자는 세 가지 결합 방법을 제시한다.
- **파라메트릭 결합**: 각 서브포스터리어를 평균 \(\mu_m\)와 공분산 \(\Sigma_m\)로 요약한 가우시안으로 근사하고, 곱을 다시 가우시안 \(\mathcal N(\mu_M,\Sigma_M)\) 으로 정리한다. 파라메트릭 추정은 Bernstein‑von Mises 정리에 기반해 대규모 데이터에서 빠르게 수렴하지만, 비가우시안 후방분포에 대해서는 점근적 편향이 존재한다.
- **비파라메트릭 결합**: 각 서브포스터리어에 커널 밀도 추정(KDE)을 적용해 가우시안 커널 \(\mathcal N(\theta;\theta^{(m)}_t,h^2I)\) 의 평균으로 표현한다. 전체 곱은 \(T^M\) 개의 가우시안 혼합으로 나타나지만, **Independent Metropolis within Gibbs (IMG)** 알고리즘을 사용해 효율적으로 하나의 혼합 성분을 선택하고 해당 가우시안에서 샘플링한다. 이 방법은 밀도 곱 추정기가 일관성을 갖기 때문에, 샘플 수 \(T\)가 무한대로 갈 때 전체 포스터리어에서 점근적으로 정확한 샘플을 제공한다.
- **반파라메트릭 결합**: 파라메트릭 가우시안 근사와 비파라메트릭 KDE 보정 함수를 곱한 형태 \(b p_m(\theta)=b f_m(\theta)\,b r_m(\theta)\) 을 사용한다. 여기서 \(b f_m\) 는 파라메트릭 가우시안, \(b r_m\) 는 KDE 기반 보정이다. 결과적으로 전체 곱은 가우시안 혼합에 비가우시안 가중치를 부여한 형태가 되며, IMG를 그대로 적용한다. 작은 샘플 수에서는 파라메트릭 근사의 빠른 수렴을, 샘플이 충분히 많아질 때는 비파라메트릭 추정의 무편향성을 동시에 확보한다.
**이론적 보장**
논문은 비파라메트릭·반파라메트릭 방법에 대해 **MSE(평균제곱오차) 수렴**과 **점근적 정확성**을 증명한다. 서브포스터리어 샘플 수 \(T\)가 증가하면 밀도 곱 추정기의 편향·분산이 모두 0에 수렴함을 보이며, 따라서 최종 샘플은 전체 포스터리어와 동일한 분포를 갖는다. 또한, 파라메트릭 방법에 대해서는 Bernstein‑von Mises 정리를 이용해 가우시안 근사의 정확도를 정량화한다.
**복잡도 및 통신 비용**
비파라메트릭 결합은 기본적으로 \(O(d\,T\,M^2)\) 연산을 필요로 하지만, 서브셋을 쌍으로 결합하는 단계적 방법을 사용하면 \(O(d\,T\,M)\) 으로 감소한다. 통신 비용은 각 머신이 \(T\) 개의 샘플(각 \(d\) 차원)만 마스터에게 전송하면 되므로 \(O(d\,T\,M)\) 스칼라에 불과하고, 온라인 전송이 가능해 전체 파이프라인을 겹쳐 실행할 수 있다.
**실험 결과**
베이지안 로지스틱 회귀, 혼합 가우시안 모델, 토픽 모델 등 다양한 베이지안 모델에 적용해, 전통적인 전체 데이터 MCMC 대비 **burn‑in 단계와 샘플링 단계 모두에서 거의 선형적인 속도 향상**을 확인한다. 파라메트릭 결합은 초기 수렴이 빠르고, 비파라메트릭·반파라메트릭 결합은 복잡한 후방분포에서도 정확한 추정치를 제공한다는 점이 강조된다.
**결론 및 의의**
본 연구는 (1) 데이터가 분산 저장된 환경, (2) 기존 MCMC 구현을 그대로 재사용하고 싶을 때, (3) 통신 비용을 최소화하면서도 정확한 베이지안 추론을 유지하고 싶을 때, 매우 실용적인 솔루션을 제공한다. 특히 “embarrassingly parallel”이라는 특성을 통해 각 머신이 독립적으로 작업하고, 최종 결합 단계만을 위해 최소한의 통신을 수행함으로써, 대규모 데이터와 고성능 클러스터 환경에서 베이지안 분석을 실용화하는 중요한 발판을 마련한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기