다중작업 정책 탐색: 상태·작업 통합 학습으로 로봇 제어 일반화
본 논문은 상태와 작업을 동시에 입력으로 하는 파라미터화된 정책 π(x, η, θ)를 제안한다. 모델 기반 정책 탐색 프레임워크인 PILCO와 결합해 여러 연속적인 작업을 하나의 비선형 피드백 정책으로 학습하고, 학습된 정책을 새로운 작업에 재학습 없이 적용할 수 있다. 실험은 카트‑폴 스윙업, 블록 적재, 텐던‑드리븐 로봇 타격 등 세 가지 로봇 시나리오에서 수행되어 데이터 효율성과 일반화 능력을 입증한다.
저자: Marc Peter Deisenroth, Peter Englert, Jan Peters
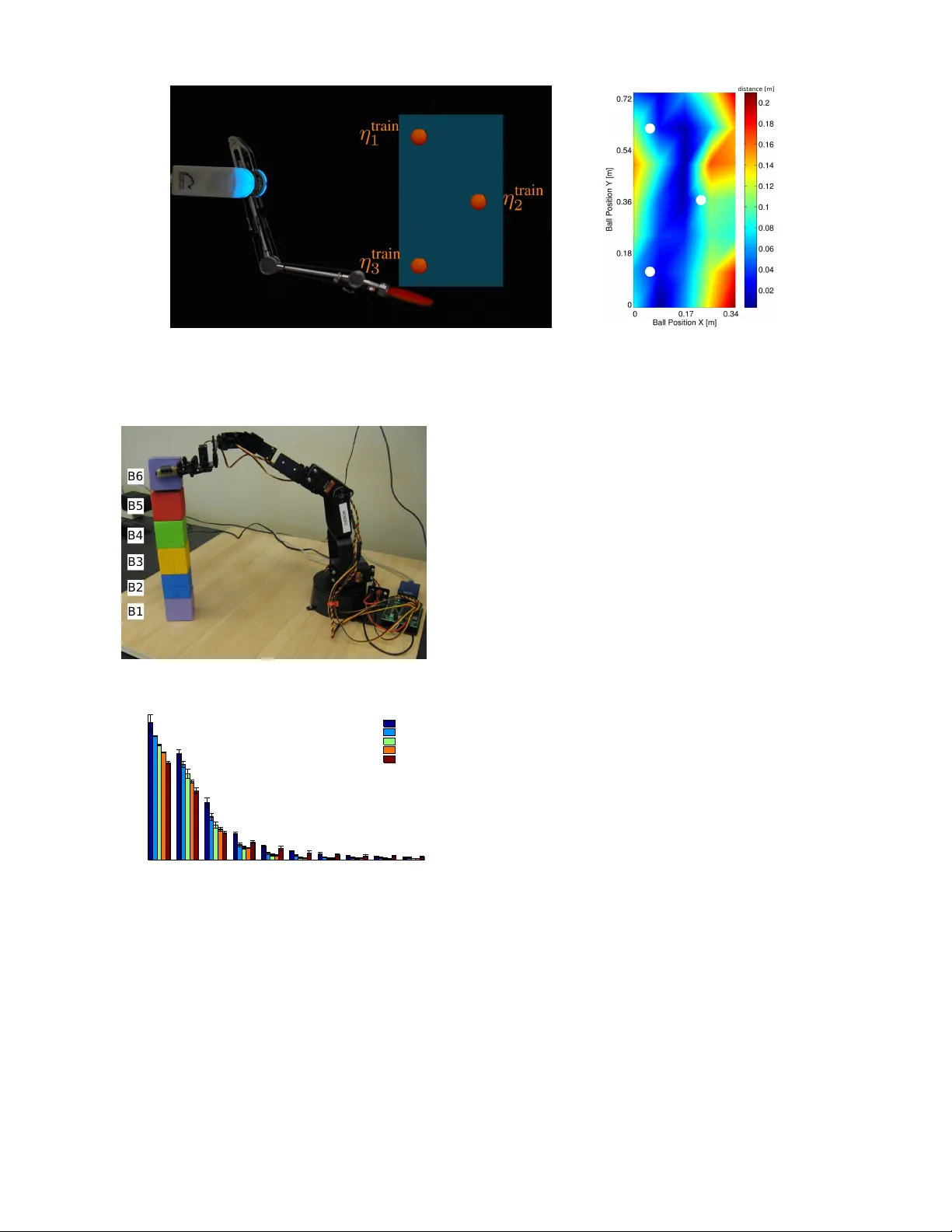
본 논문은 로봇 및 강화학습 분야에서 “다중작업 정책 탐색(Multi‑Task Policy Search)”이라는 새로운 방법론을 제시한다. 전통적인 강화학습에서는 각 작업마다 별도의 정책을 학습하는 것이 일반적이지만, 작업이 연속적이거나 수가 많을 경우 이는 비현실적이다. 저자들은 이러한 문제를 해결하기 위해 정책을 상태 x와 작업 η를 동시에 입력받는 함수 π(x, η, θ)로 정의한다. 이렇게 하면 하나의 파라미터 집합 θ만으로도 다양한 작업을 수행할 수 있다.
학습 프레임워크는 모델 기반 정책 탐색 알고리즘인 PILCO를 기반으로 한다. 초기에는 무작위 제어를 통해 데이터를 수집하고, Gaussian Process(GP)를 이용해 시스템 동역학 f(x, u)를 확률적으로 모델링한다. GP는 예측 평균과 공분산을 제공하므로, 장기 예측 단계에서 순간 매칭(moment‑matching) 기법을 사용해 상태 분포를 가우시안으로 근사한다. 이때 정책 입력은 상태와 작업을 결합한 확장된 벡터 g(x, η)이며, g는 η−x(선형 관계) 혹은 η 자체(비선형 관계)로 정의될 수 있다.
다중작업 학습은 모든 훈련 작업 η_train_i에 대해 기대 장기 비용 J(θ)=1/M∑_i J(θ, η_train_i)를 최소화하는 형태로 전개된다. 비용 함수 c(x)에는 작업‑특정 목표(예: 목표 위치)와 일반적인 제어 비용이 포함된다. 비용과 그라디언트는 GP 기반의 상태‑작업 결합 분포를 통해 분석적으로 계산되며, 이는 BFGS와 같은 2차 최적화 기법에 바로 적용될 수 있다. 또한, 학습 단계에서 작업에 대한 불확실성 Σ_η를 도입해 정규화 효과와 일반화 성능을 향상시킨다.
실험은 세 가지 로봇 시나리오에서 수행되었다. 첫 번째는 카트‑폴 스윙업 문제로, 목표 각도가 연속적으로 변하는 작업 집합에 대해 단일 정책이 매끄럽게 제어 신호를 조정하는 모습을 시각적으로 확인하였다. 두 번째는 저비용 로봇 팔이 여러 위치에 블록을 적재하는 작업으로, 기존 방법 대비 적은 샘플 수로 높은 성공률을 달성하였다. 세 번째는 텐던‑드리븐 로봇이 인간 시연을 모방해 다양한 목표를 타격하는 과제로, 실제 로봇에서 실시간으로 새로운 작업에 적용 가능함을 보여준다. 모든 실험에서 제안된 다중작업 정책은 데이터 효율성(수십 회의 시뮬레이션/실험)과 작업 일반화 능력(보지 못한 목표에 대한 성공적인 제어)에서 기존 단일작업 학습이나 계층적 로컬 정책 결합 방식보다 우수한 성능을 보였다.
결론적으로, 상태와 작업을 동시에 고려한 비선형 피드백 정책과 모델 기반 PILCO의 결합은 로봇 제어에서 다중작업 학습을 실용적으로 구현할 수 있는 강력한 도구임을 입증한다. 향후 연구에서는 더 복잡한 작업 분포, 비정형 작업 정의, 그리고 실시간 적응 메커니즘을 포함한 확장이 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기