구조화된 사전지식으로 향상된 희소 표현 기반 하이퍼스펙트럼 이미지 분류
본 논문은 희소 표현 분류기(SRC)에 다양한 구조화된 정규화를 결합하여 하이퍼스펙트럼 이미지(HSI) 분류 성능을 향상시키는 방법을 제시한다. 기존 ℓ₁ 정규화 외에 공동 희소성, 라플라시안 정규화, 그룹 라쏘, 희소 그룹 라쏘, 저계수(rank) 정규화 및 새롭게 제안한 저계수-그룹 정규화를 비교·평가한다. 실험 결과, 특히 저계수-그룹 정규화가 다른 방법들을 능가하며, 공간적·스펙트럼적 상관관계를 효과적으로 활용함을 확인하였다.
저자: Xiaoxia Sun, Qing Qu, Nasser M. Nasrabadi
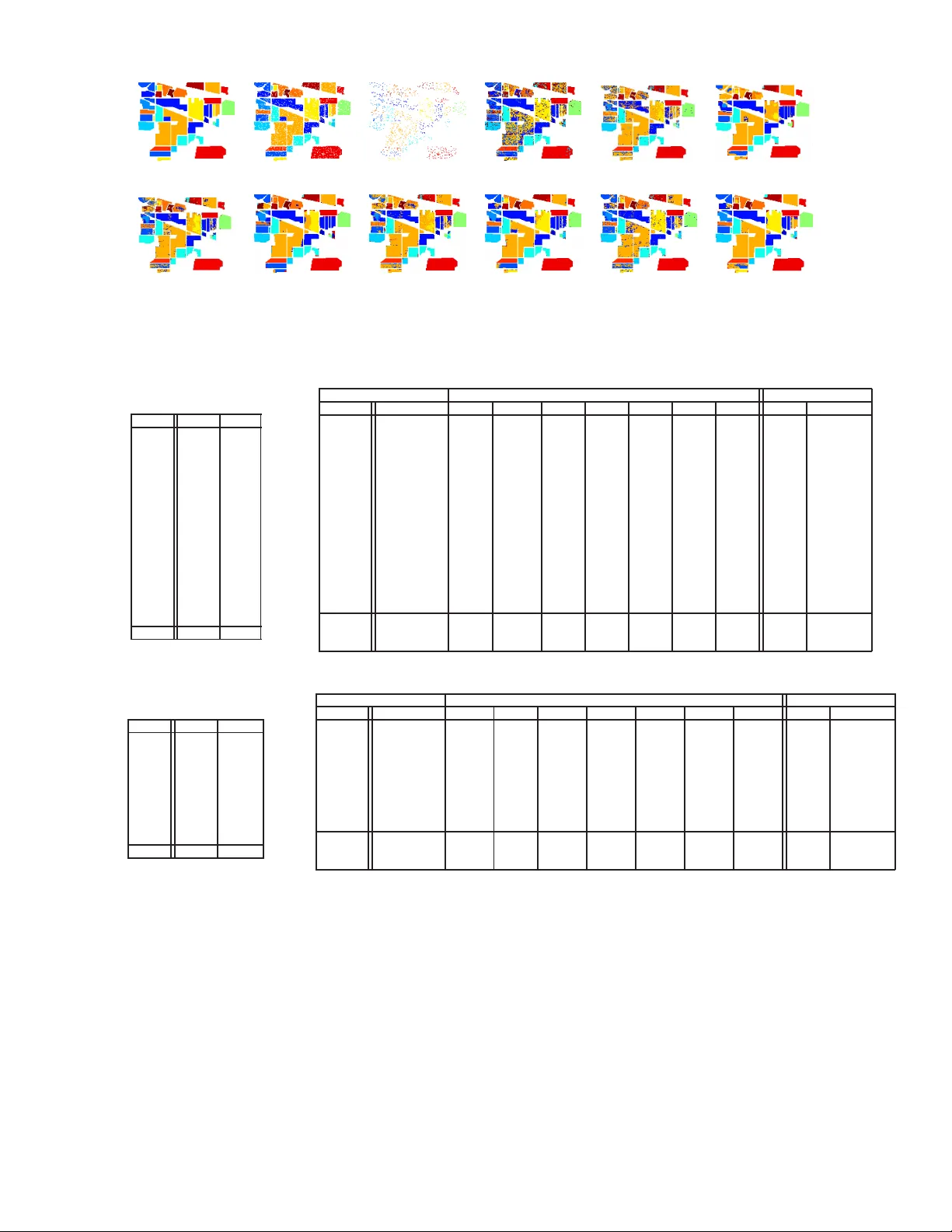
본 논문은 하이퍼스펙트럼 이미지(HSI) 분류에서 희소 표현 분류기(Sparse Representation Classifier, SRC)의 한계를 극복하고자, 다양한 구조화된 정규화(prior)를 도입하여 성능을 향상시키는 방법을 체계적으로 연구한다. 기존 SRC는 테스트 픽셀 y∈ℝ^P 를 전체 훈련 샘플(딕셔너리) A∈ℝ^{P×N} 의 선형 결합으로 표현하고, ℓ₁ 정규화(‖x‖₁) 를 통해 계수 벡터 x를 희소하게 만든다. 그러나 HSI는 밴드 수가 많고 딕셔너리 원자 간 상관도가 높아, 단순 ℓ₁ 정규화만으로는 불안정하고 클래스 구분력이 떨어진다. 이를 보완하기 위해 논문은 세 가지 큰 축으로 구조화된 정규화를 분류한다.
첫 번째 축은 이웃 픽셀 간의 공간·스펙트럼 상관관계를 활용한다. 공동 희소성(Joint Sparsity, JS)은 T개의 이웃 픽셀을 하나의 행렬 Y에 모아, 모든 픽셀이 동일한 원자 집합을 선택하도록 ℓ₂,₁ 정규화(‖X‖_{1,2}) 를 적용한다. 이는 행이 희소한 행렬 X를 유도해 동일 서브딕셔너리 원소가 여러 픽셀에 공유되게 함으로써 동일 물질 영역에서 강력한 일관성을 제공한다. 그러나 경계 영역에서는 과도한 제약으로 오분류가 발생한다. 이를 보완한 것이 라플라시안 희소성(Laplacian Sparsity, LS)이다. 픽셀 간 유사도 행렬 W를 정의하고 정규화된 라플라시안 L=I−D^{-1/2}WD^{-1/2} 를 이용해 트레이스 형태의 정규화(tr(XLX^T)) 를 추가한다. LS는 유사한 픽셀은 계수가 비슷하도록, 서로 다른 픽셀은 차이를 크게 유지하도록 유도해 JS보다 유연하게 경계와 혼합 영역을 처리한다. W는 Sparse Subspace Clustering 기법을 통해 추정한다.
두 번째 축은 딕셔너리 자체의 클래스별 그룹 구조를 이용한다. 그룹 라쏘(Group Lasso, GS)는 각 클래스별 서브딕셔너리 G_g 를 하나의 그룹으로 보고, ∑_g w_g‖x_g‖₂ 형태의 정규화를 적용한다. 이는 특정 클래스 전체가 선택되거나 배제되는 그룹 수준의 희소성을 강제한다. 그러나 그룹 내부의 모든 원자가 활성화될 위험이 있다. 이를 해결하기 위해 희소 그룹 라쏘(Sparse Group Lasso, SGS)에서는 GS에 전체 ℓ₁ 정규화(λ‖x‖₁)를 추가해 그룹 내부에서도 원자 수준의 희소성을 확보한다. 협업 형태(Collaborative Sparse Group Lasso, CHiLasso)는 다중 이웃 픽셀을 동시에 고려해 ∑_g w_g‖X_g‖₂ + λ‖X‖₁ 로 최적화한다.
세 번째 축은 저계수(Low-Rank, LR) 정규화를 도입한다. 이웃 픽셀들의 계수 행렬 X에 핵노름(‖X‖_*) 를 적용해 행렬이 낮은 차원을 갖도록 강제한다. 이는 동일 서브스페이스에 속하는 픽셀들이 비슷한 선형 조합을 사용하도록 하여, 공동 희소성보다 더 유연하게 상관관계를 포착한다. 저계수-그룹 정규화(Low-Rank Group, LRG)는 LR과 GS를 결합한 형태로, 각 클래스별 서브행렬 X_g 에 대해 핵노름을 구하고 이를 합산한다(∑_g w_g‖X_g‖_*). 하나의 정규화 항만으로 (1) 그룹 간 희소성(어떤 클래스가 선택되는가)과 (2) 그룹 내부 저계수(그 내부에서의 상관관계) 두 가지를 동시에 달성한다. 이는 기존 CHiLasso가 두 개의 정규화 항을 필요로 하는 점을 간소화하면서도, 실험적으로 가장 높은 정확도와 κ 값을 기록한다.
**최적화 기법**
- ℓ₁ 기반 문제는 ADMM 혹은 SpaRSA 로 해결한다.
- 라플라시안 정규화는 수정된 Feature‑Sign Search(FSS) 알고리즘을 사용한다.
- 저계수 및 저계수‑그룹 정규화는 Singular Value Thresholding(SVT) 기반 근접 연산을 포함한다.
**실험 설계**
두 개의 실제 HSI 데이터셋과 하나의 toy example을 사용한다.
1. Indian Pine (AVIRIS) – 145×145, 220 밴드(20 noisy 제거 후 200), 16 클래스. 훈련 샘플 997개(≈10.6%), 나머지 테스트.
2. University of Pavia (ROSIS) – 610×340, 115 밴드(12 noisy 제거 후 103), 9 클래스. 훈련 샘플 997개(≈2.3%).
3. Toy example – Indian Pine의 클래스 2와 14에서 각각 30픽셀씩 선택, 구조화된 정규화가 생성하는 희소 패턴을 시각화.
각 정규화 별로 전체 정확도(OA), 평균 정확도(AA), Kappa(κ)를 측정하고, 시각적 분류 맵을 비교한다. 최적화는 ADMM/SpaRSA와 FSS 두 가지 구현을 사용해 성능 차이를 확인한다.
**주요 결과**
- Indian Pine에서는 LRG가 OA 92.58%, κ 0.923을 달성, LS와 JS는 각각 OA 83.74%와 71.17%에 머물렀다. 저계수(LR)도 86.46% 수준으로 괄목할 만한 향상을 보였지만, LRG가 가장 일관되게 우수했다.
- Pavia에서는 LRG가 OA 81.02%, κ 0.843을 기록, 특히 저계수(LR)와 그룹 라쏘(GS)가 각각 79.07%와 80.81%에 그쳤다. LS와 JS는 각각 66.51%와 74.05% 수준으로 낮았다.
- 클래스별 분석에서 훈련 샘플이 매우 적은 클래스(예: 클래스 7, 9)에서는 모든 방법이 낮은 정확도를 보였지만, 전반적으로 LRG가 가장 높은 평균 정확도와 Kappa를 유지했다.
- 시각적으로 LRG는 경계와 혼합 영역을 명확히 구분하고, 잡음에 대한 강인성을 보여준다.
**의의**
구조화된 정규화는 HSI의 고차원·고상관 특성을 효과적으로 활용한다는 점에서 큰 의미가 있다. 특히 LRG는 하나의 정규화 항만으로 (1) 그룹 간 선택, (2) 그룹 내부 저계수라는 두 가지 복합 정보를 동시에 포착함으로써 구현 복잡성을 크게 낮춘다. 이는 실제 현장 적용 시 파라미터 튜닝과 연산 비용을 절감할 수 있다.
**한계**
- 핵노름 연산은 대규모 딕셔너리와 다중 이웃을 다룰 때 계산 비용이 높다.
- 정규화 파라미터 λ와 그룹 가중치 w_g 의 선택이 성능에 민감하며, 자동화된 선택 방법이 필요하다.
- 매우 적은 훈련 샘플(특히 소수 클래스)에서는 여전히 과적합 위험이 존재한다.
**향후 연구**
1. 딥러닝 기반 사전 학습과 구조화 정규화를 결합한 하이브리드 모델 개발.
2. 온라인/증분 핵노름 최적화 기법을 도입해 실시간 처리 가능성 탐색.
3. 다중 스케일 이웃 정의와 동적 가중치 학습을 통해 경계 영역에서의 정밀도 향상.
4. 파라미터 자동 튜닝을 위한 베이지안 최적화 혹은 메타러닝 적용.
본 논문은 구조화된 정규화가 HSI 분류에 미치는 영향을 체계적으로 정량·정성 분석함으로써, 차세대 고성능 분류기 설계에 중요한 지침을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기