고차원 데이터에서 분류기 기반 특징 선택: 필터와 래퍼 접근 비교
본 논문은 4000개의 유전자 발현 특성을 가진 216개의 임상 샘플을 대상으로, 필터 방식(단변량 t‑검정)과 래퍼 방식(순차 전진 선택)을 QDA와 LDA 분류기에 결합하여 특징 선택을 수행한다. 홀드아웃과 10‑폴드 교차 검증을 통해 오분류율(MCE)을 평가한 결과, 필터 기반 단순 선택이 QDA에서 0.0536, LDA에서 0.0200의 낮은 오류율을 보이며, 래퍼 방식보다 우수함을 확인하였다. 과다 특징 사용 시 과적합이 발생함을 시각…
저자: Vijendra Singh, Shivani Pathak
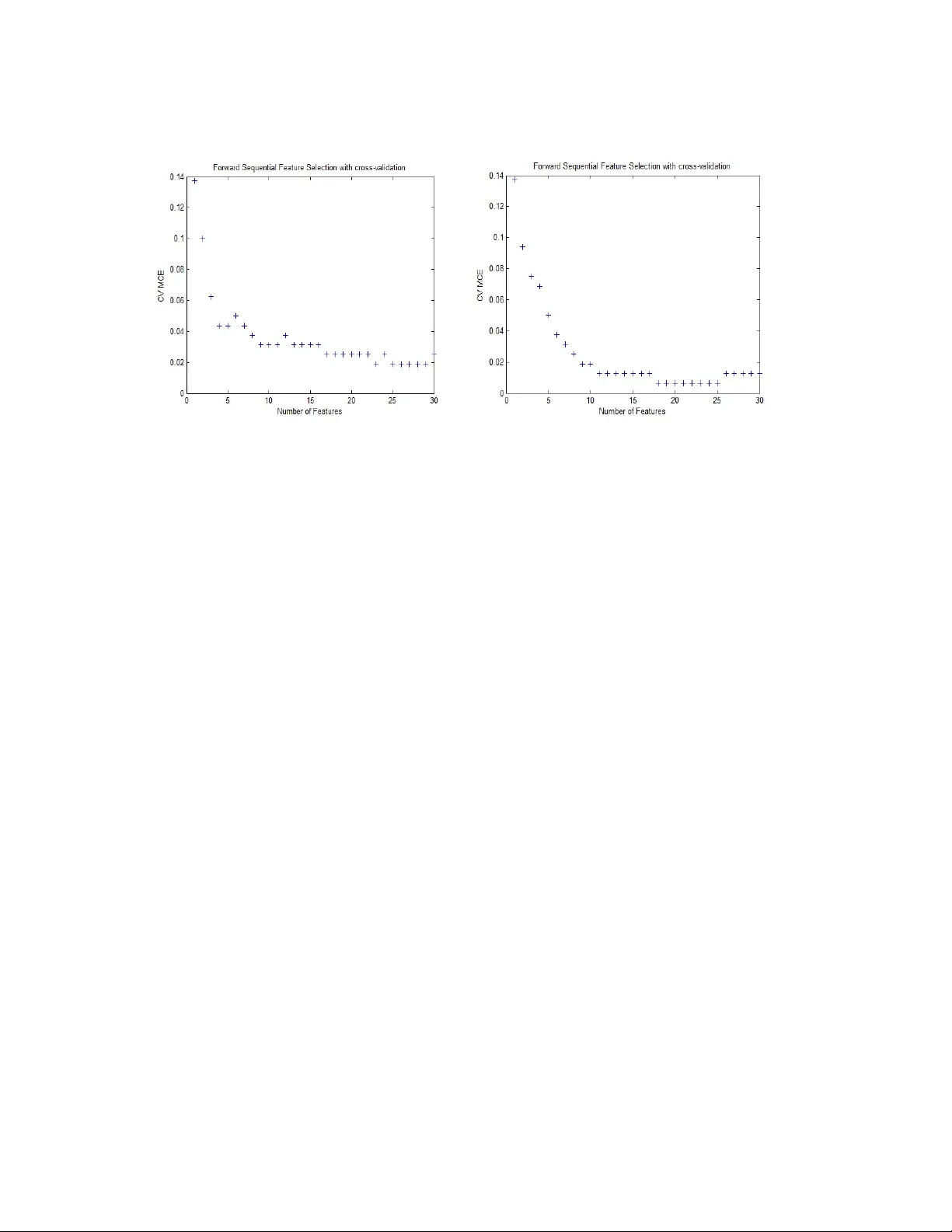
본 논문은 고차원 바이오인포매틱스 데이터에서 특징 선택이 분류 성능에 미치는 영향을 조사한다. 연구 대상은 216개의 임상 샘플과 4000개의 유전자 발현 피처이며, 이를 훈련 집합(160개)과 테스트 집합(56개)으로 분할하였다. 특징 선택 방법으로는 널리 사용되는 필터 방식과 래퍼 방식을 각각 적용했으며, 두 방법 모두 QDA와 LDA 두 분류기에 결합하여 성능을 비교하였다.
필터 단계에서는 각 피처에 대해 단변량 t‑검정을 수행해 p‑값을 계산하고, p‑값이 작을수록 두 클래스 간 구분력이 높다고 판단한다. 전체 피처 중 약 35%가 p‑값이 0에 근접하고, 50%가 0.05 이하인 것으로 나타나 약 2000개의 피처가 통계적으로 유의함을 확인하였다. 이러한 피처들을 p‑값 순으로 정렬한 뒤, 상위 N개의 피처를 선택하고 N을 변화시키면서 테스트 셋에 대한 Misclassification Error(MCE)를 측정하였다. QDA에서는 20개, LDA에서는 15개의 피처가 최소 MCE(각각 0.0536, 0.0200)를 달성했으며, 그 이상 피처를 추가하면 오버피팅이 발생해 오류율이 상승하였다.
래퍼 단계에서는 필터에서 추출한 150개의 후보 피처를 대상으로 순차 전진 선택(Sequential Forward Selection, SFS)을 적용하였다. SFS는 현재 선택된 피처 집합에 하나씩 피처를 추가하면서, 각 후보 집합에 대해 10‑폴드 교차 검증을 수행해 평균 MCE를 계산한다. MCE가 최소가 되는 시점에서 선택을 종료했으며, QDA와 LDA 모두 9개의 피처가 최적점으로 도출되었다. 최종 테스트 셋에 대한 MCE는 QDA 0.0714, LDA 0.0893으로, 필터 방식보다 높은 오류율을 보였다.
알고리즘 구현 과정에서 사용된 평가 지표는 J= XᵀS⁻¹X 형태의 통계량이며, 이는 선택된 피처 집합의 분산-공분산 구조를 고려한다. 또한, 교차 검증 과정에서 stratified 10‑fold 방식을 채택해 각 폴드가 클래스 비율을 유지하도록 하여 평가의 편향을 최소화하였다.
실험 결과는 다음과 같이 정리된다. (1) 필터 기반 단순 선택이 QDA와 LDA 모두에서 낮은 MCE를 기록했으며, 특히 LDA에서 0.0200이라는 매우 낮은 오류율을 달성했다. (2) 래퍼 기반 순차 전진 선택은 피처 수를 크게 줄이는 장점이 있지만, 이 경우에도 최적 피처 수가 9개에 불과했으며, 전체 피처를 활용한 필터 방식에 비해 성능이 뒤처졌다. (3) 피처 수가 증가함에 따라 MCE가 급격히 상승하는 구간이 존재함을 그래프를 통해 명확히 보여주었으며, 이는 과적합 현상의 전형적인 예시이다.
결론적으로, 고차원 데이터에서 샘플 수가 제한된 상황에서는 계산 비용이 낮고, 통계적 유의성을 기반으로 한 필터 방식이 효과적인 특징 선택 전략임을 확인하였다. 또한, QDA와 LDA와 같은 선형/비선형 판별 분석기와 결합했을 때, 적절한 피처 수(20~30개 정도)를 선택하면 과적합을 방지하면서도 높은 분류 정확도를 유지할 수 있다. 향후 연구에서는 하이브리드 접근(필터 → 래퍼)이나, 비선형 모델(예: SVM, 랜덤 포레스트)과의 결합을 통해 더욱 정교한 특징 선택 방법을 모색할 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기