깊이와 움직임을 동시에 배우는 무감독 학습 모델
본 논문은 복수의 카메라와 영상 프레임 사이의 상관관계를 학습해, 스테레오 이미지 쌍과 비디오 시퀀스로부터 깊이(시차)와 움직임을 동시에 추정하는 단일 아키텍처와 무감독 학습 방법을 제안한다. 생물학적 ‘복합 세포’ 모델을 모방한 에너지 기반 복합 셀 유닛을 이용해 픽셀 간 상관을 인코딩하고, 동기화 오토인코더(Synchrony Autoencoder)를 통해 효율적인 1‑층 학습을 수행한다. 학습된 필터는 KITTI 스테레오 데이터와 Holly…
저자: Kishore Konda, Rol, Memisevic
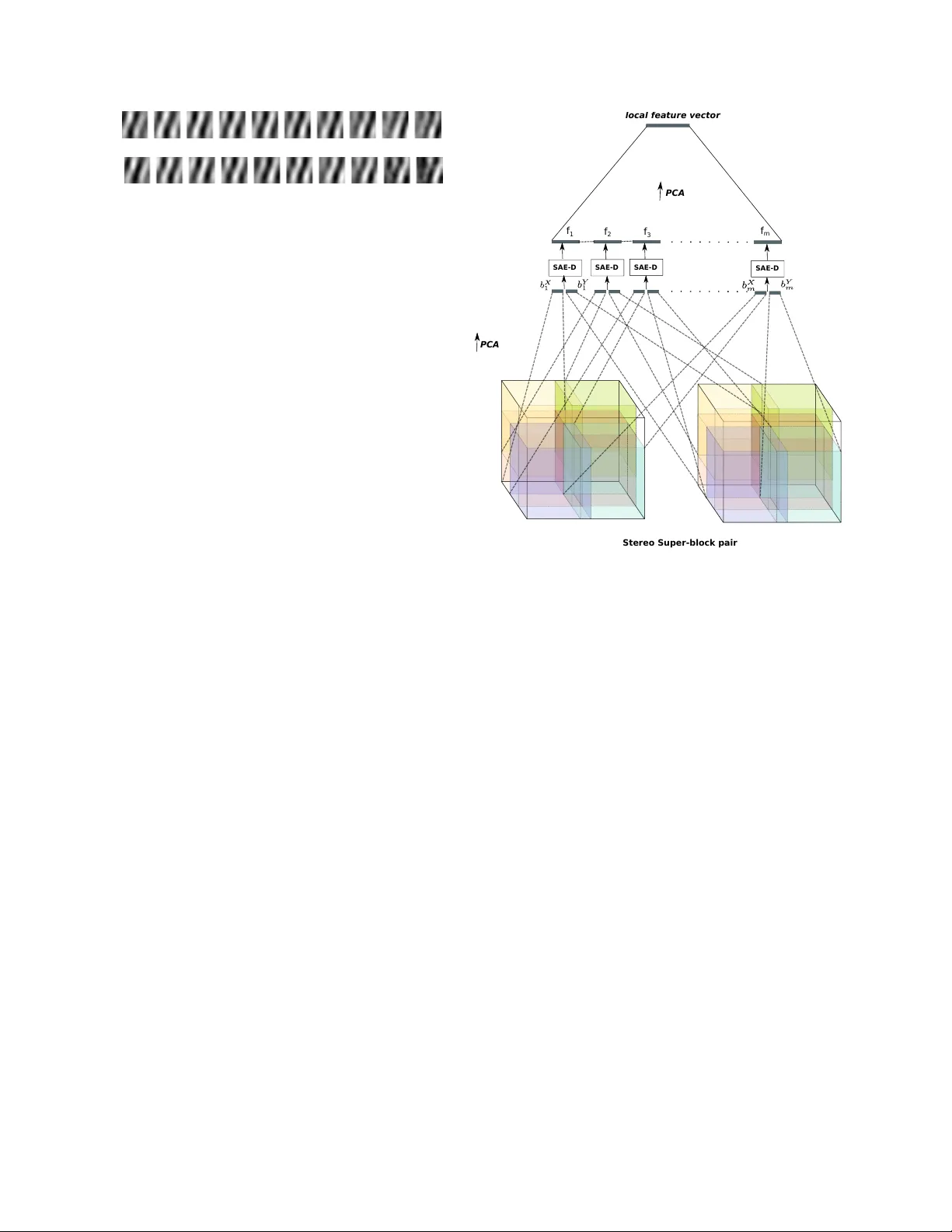
본 논문은 3‑차원(3‑D) 깊이와 시간적 움직임을 동시에 추정할 수 있는 통합 무감독 학습 프레임워크를 제시한다. 저자들은 인간 시각 시스템의 ‘복합 세포’(complex cell) 메커니즘을 모방한 에너지 모델을 기반으로, 이미지 쌍 혹은 비디오 시퀀스 사이의 픽셀 상관관계를 학습한다. 핵심 아이디어는 두 이미지(또는 프레임) 사이의 변환을 필터의 위상 이동으로 모델링하고, 이 변환을 곱셈적 상호작용을 통해 은닉 유닛에 인코딩하는 것이다.
1. **이론적 배경**
- 깊이와 움직임 모두 ‘픽셀 대응’ 문제에 귀속된다. 스테레오 경우는 서로 다른 시점의 동일 3‑D 점을, 움직임 경우는 시간에 따라 변하는 동일 점을 찾는 것이 목표이다.
- 기존 접근법은 (i) 패치 매칭 기반, (ii) 위상·주파수 기반 두 가지가 있다. 저자들은 두 번째 접근법을 채택해, 생물학적으로 타당하고 데이터‑드리븐 학습이 가능한 모델을 설계한다.
- 에너지 모델은 두 눈(또는 두 프레임) 각각에 쌍을 이루는 수용체 필터가 존재하고, 이 필터가 위치‑시프트(시차)와 위상 차이를 갖는다는 가정 하에, 필터 응답의 제곱합이 변환에 민감하게 반응한다는 원리다.
2. **Synchrony Autoencoder (SAE) 설계**
- 입력 이미지 쌍 x, y에 대해 선형 투영 행렬 Wₓ, Wᵧ를 학습한다. 각각의 투영 결과 fₓ = Wₓ x, fᵧ = Wᵧ y를 ‘요인(factor)’이라 부른다.
- 은닉 유닛 h는 σ(fₓ ⊙ fᵧ) (⊙는 원소별 곱, σ는 시그모이드)로 정의된다. 이는 두 요인 사이의 동기화(synchrony)를 측정한다.
- 재구성은 x̂ = Wₓᵀ (h ⊙ fᵧ), ŷ = Wᵧᵀ (h ⊙ fₓ) 로 수행되며, 가중치는 공유(tied)한다.
- 손실은 재구성 오차와 입력에 대한 은닉 유닛 야코비안 제곱 노름(수축 정규화) λ·‖Jₑ‖²의 가중합이다. 이는 은닉 표현이 입력 변화에 부드럽고 희소하도록 유도한다.
3. **깊이 학습 (Stereo Pair Model)**
- 16×16 픽셀 패치를 10⁵개 수집해 학습한다. 패치 크기는 최대 시차를 포함하도록 설정한다.
- 학습된 필터는 Gabor 형태에 수렴하지만, 데이터에 맞게 최적화된다.
- 깊이 맵을 추정하려면, 학습된 모델에 새로운 스테레오 쌍을 입력하고, 은닉 유닛 h를 이용해 변환을 추정한다. 필요 시, 제한된 ground‑truth를 이용해 캘리브레이션을 수행해 명시적 깊이 값을 얻는다.
4. **시간적 확장 및 다중 뷰 모델**
- 두 카메라 채널을 각각 X, Y 시퀀스로 연결하고, 각 프레임에 동일 필터를 적용한다.
- **SAE‑D (Depth Encoding)**: H_D = σ(Fₓ·Fᵧ) 로 정의, 여기서 Fₓ, Fᵧ 는 시퀀스 전체에 대한 요인 합이다. 이는 스테레오 쌍 간 동기화를 포착한다.
- **SAE‑M (Motion Encoding)**: H_M = σ((Fₓ)²) (또는 σ((Fᵧ)²)) 로 정의, 이는 동일 카메라 내 프레임 간 곱을 통해 움직임을 인코딩한다.
- **SAE‑MD (Joint Depth‑Motion)**: H_MD = σ((Fₓ)²·(Fᵧ)²) 로 정의, 시간적 진화와 시차 정보를 동시에 반영한다.
5. **관심점 검출**
- 학습된 선형 필터의 응답 크기 ‖H‖₁이 큰 위치를 관심점으로 선택한다. 이는 에지·운동이 강한 영역에서 자연스럽게 높은 응답을 보이기 때문이다.
6. **실험**
- **KITTI 스테레오**: 194개의 학습 이미지 쌍과 195개의 테스트 쌍을 사용. 이미지 해상도를 300×100으로 다운샘플링하고, 30% 픽셀에만 깊이 라벨이 존재한다. 학습된 SAE‑D 모델은 평균 절대 깊이 오차에서 기존 Gabor‑기반 방법보다 우수한 성능을 보였다.
- **Hollywood3D 행동 인식**: 다중 카메라 비디오 시퀀스를 사용해 행동 분류 실험을 수행. SAE‑D, SAE‑M, SAE‑MD 각각을 Bag‑of‑Features 파이프라인에 적용했으며, 특히 SAE‑MD가 가장 높은 정확도를 기록했다. 이는 깊이와 움직임 정보를 동시에 활용했을 때 행동 구분에 큰 이점을 제공함을 의미한다.
- 전체 파이프라인은 손잡이 특징을 거의 사용하지 않았음에도 불구하고, 기존 최첨단 3‑D 모션 특징을 크게 앞섰다.
7. **결론 및 향후 과제**
- 깊이와 움직임을 동일한 에너지 기반 구조로 무감독 학습할 수 있음을 입증하였다.
- 복합 세포 모델을 현대적인 오토인코더 프레임워크에 통합해, 1‑층 학습만으로도 강력한 3‑D 표현을 얻을 수 있다.
- 향후 연구에서는 다층 구조, 비디오‑스테레오 간 전이 학습, 그리고 실시간 적용을 위한 경량화 등이 제안된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기