잠재 소스 모델 기반 비모수 시계열 분류
본 논문은 시계열을 소수의 잠재 원천(라틴 소스)으로 가정하고, 이를 이용한 가중 다수결 투표와 최근접 이웃 분류기의 비모수적 방법을 제안한다. 모델 하에서 훈련 데이터와 관측 길이에 따라 오류 상한을 비대칭적으로 제시하고, 합성 데이터와 트위터 트렌드 예측 실험을 통해 제안 방법이 적은 관측으로도 높은 정확도를 달성함을 보인다.
저자: George H. Chen, Stanislav Nikolov, Devavrat Shah
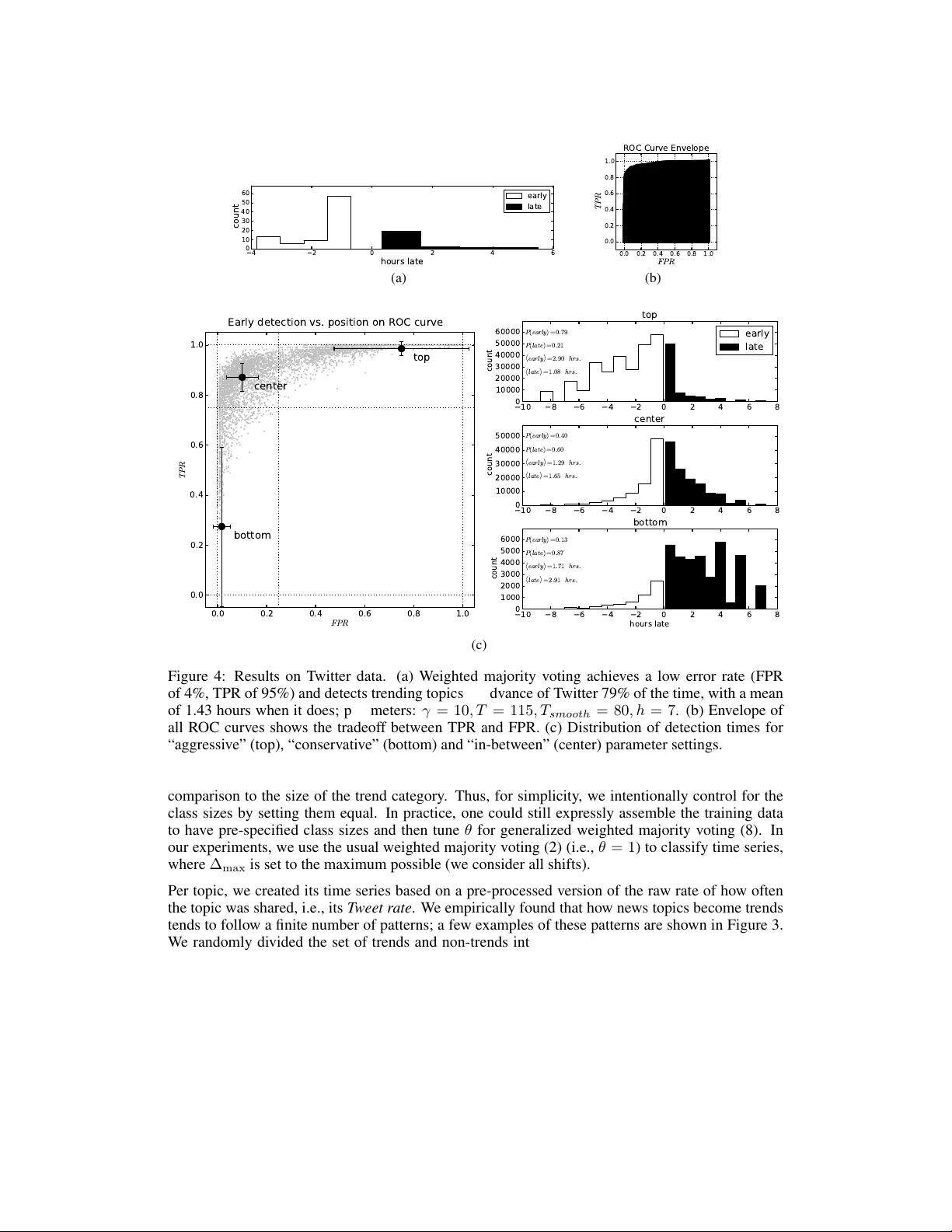
본 논문은 시계열 분류 문제에 대해 “실제 데이터는 소수의 전형적인 패턴(잠재 소스)으로 구성된다”는 가설을 제시하고, 이를 기반으로 비모수적 분류 방법을 설계·분석한다.
1. **배경 및 동기**
최근 시계열 데이터가 폭증함에 따라 다양한 분류 기법이 제안되었지만, 가장 단순한 최근접 이웃(k‑NN) 방식이 여러 데이터셋에서 뛰어난 성능을 보인다. 그러나 기존 연구는 주로 실험적 비교에 머물며, 언제·왜 k‑NN이 효과적인지에 대한 이론적 근거가 부족했다. 저자들은 트위터 트렌드 예측과 같은 실제 응용에서 “트렌드가 되는 방식은 몇 가지 유형에 불과하다”는 직관을 바탕으로, 잠재 소스 모델을 도입한다.
2. **잠재 소스 모델 정의**
- **잠재 소스 집합 V**: m개의 시계열 v(t) 로 구성되며, 각 소스는 라벨 +1(트렌드) 혹은 –1(비트렌드)를 가진다.
- **생성 과정**: (i) V를 균등하게 선택, (ii) 정수 시간 이동 Δ∈{0,…,Δ_max} 를 무작위 선택, (iii) 잡음 E(t) (i.i.d. 서브가우시안, 파라미터 σ) 를 더해 관측 시계열 S(t)=V(t+Δ)+E(t) 를 만든다.
- 라벨은 원본 소스와 동일하게 유지된다.
이 모델은 소스의 형태에 대한 어떠한 가정도 하지 않으며, 시간 이동과 잡음만을 허용한다.
3. **가중 다수결 투표 (Weighted Majority Voting, WMV)**
- 훈련 데이터 R⁺, R⁻ 를 이용해 각 훈련 시계열 r에 대해 거리 d_T(r,s)=min_{Δ∈D}‖r∗Δ−s‖²_T 를 계산한다.
- 가중치 e^{−γ d_T(r,s)} 로 라벨에 투표하고, 전체 가중합이 큰 라벨을 최종 예측한다.
- γ는 영향 반경을 조절하는 파라미터이며, γ가 크게 설정되면 가장 가까운 이웃에만 큰 가중치가 부여되어 k‑NN과 동일한 동작을 근사한다.
4. **최근접 이웃 분류기와의 관계**
- k‑NN은 WMV에서 γ→∞ (또는 k개의 가장 작은 거리만 선택) 로 제한한 경우와 동일하다.
- 따라서 WMV는 k‑NN의 일반화된 형태이며, 이론적으로는 두 방법 모두 동일한 오류 상한을 갖는다.
5. **이론적 성능 보장**
- **갭 정의**: G(T)=min_{r⁺∈R⁺, r⁻∈R⁻, Δ⁺,Δ⁻∈D}‖r⁺∗Δ⁺−r⁻∗Δ⁻‖²_T 로, 두 라벨 집합 사이의 최소 거리(시간 이동 허용)를 측정한다.
- **정리 1 (WMV)**: 훈련 샘플 n>β·m·log m (β>1) 일 때, 오류 확률은
P(error) ≤ (θ m⁺+m⁻)/(θ m⁺+m⁻)·(2Δ_max+1)·n·exp
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기