KL‑UCB 알고리즘의 최적성 및 확장
KL‑UCB는 제한된 확률 보상을 갖는 다중 무장 밴딧 문제에서 기존 UCB 계열보다 엄격히 작은 후회를 보장한다. 특히 베르누이 보상에서는 라이·로드빈스 하한을 정확히 달성하며, 지수형 가족 등 보다 일반적인 분포에도 KL‑UCB를 적절히 변형하면 최적성을 유지한다. 실험 결과는 짧은 시간 horizon에서도 KL‑UCB가 다른 최신 알고리즘보다 일관되게 우수함을 보여준다.
저자: Aurelien Garivier, Olivier Cappe
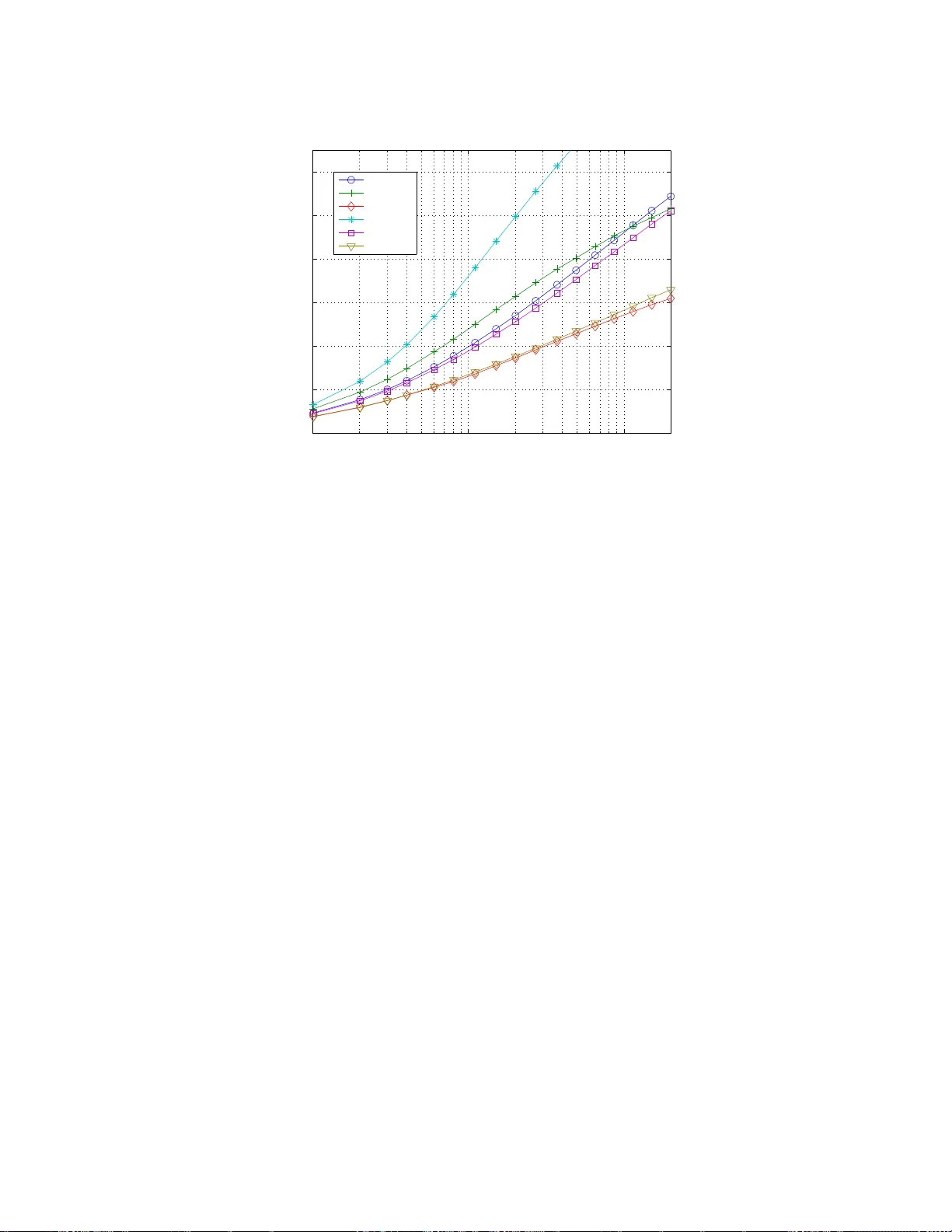
이 논문은 제한된 확률 보상을 갖는 다중 무장 밴딧 문제에 대해 KL‑UCB(Kullback‑Leibler Upper Confidence Bound) 알고리즘을 제안하고, 그 이론적 성능과 실험적 효율성을 포괄적으로 분석한다. 먼저, 문제 설정을 명확히 정의한다. 각 팔 a∈{1,…,K}는 독립적인 보상 시퀀스 X_{a,t}를 가지며, 보상은
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기