관계 유사성 순위 매김: 생물·정보 네트워크의 아날로지 기반 접근법
본 논문은 주어진 객체 쌍 집합 S 에 대해 새로운 쌍 A:B 가 S 와 얼마나 유사한 관계를 맺는지를 베이지안 집합(Bayesian Sets) 프레임워크와 함수 공간 유사도 측정을 결합해 순위화하는 방법을 제안한다. 객체 특징과 관계 존재 여부를 나타내는 링크 행렬만으로 학습하며, 텍스트, 웹 페이지, 단백질‑단백질 상호작용 등 다양한 도메인에 적용 가능함을 실험을 통해 입증한다.
저자: Ricardo Silva, Katherine Heller, Zoubin Ghahramani
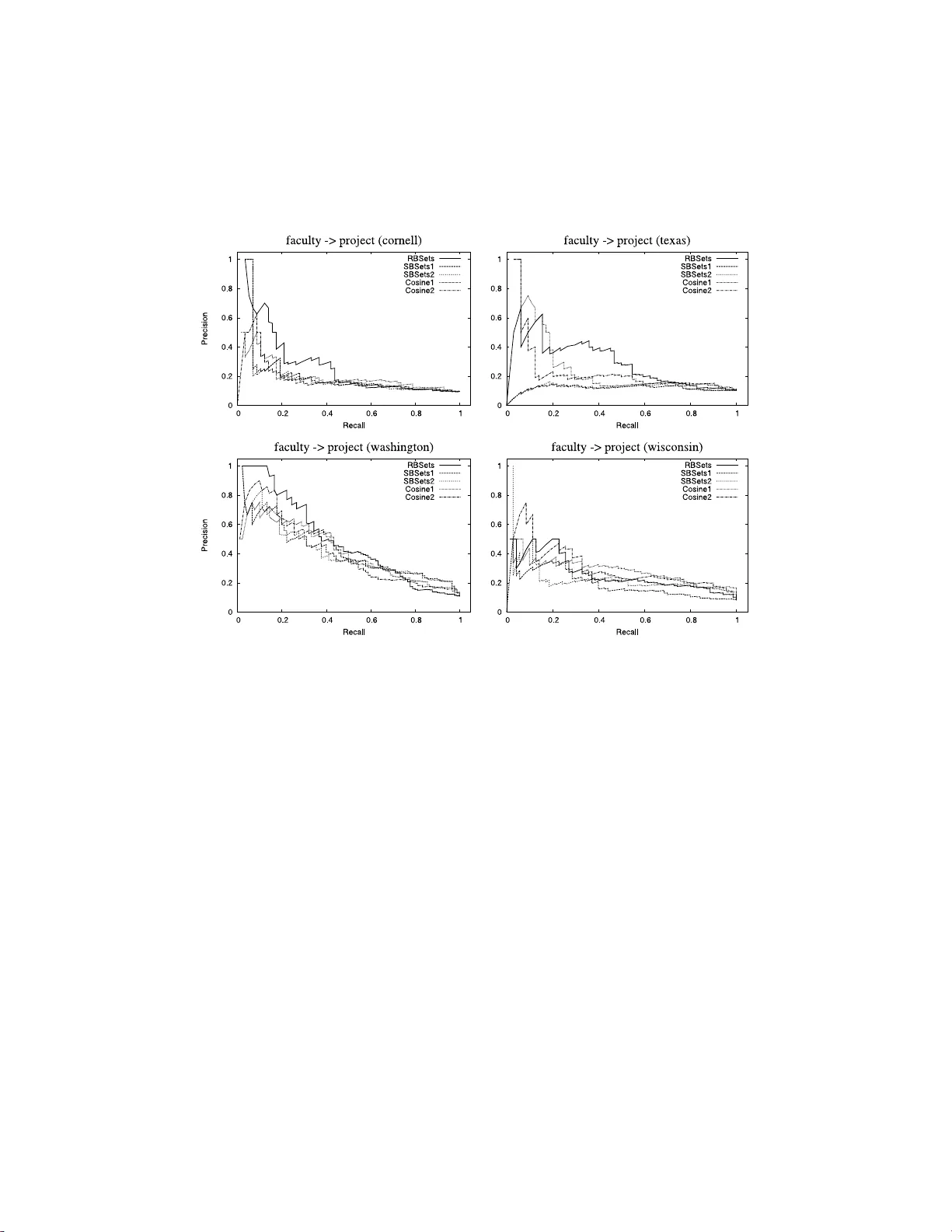
본 논문은 아날로지 추론을 데이터 과학에 적용하기 위한 새로운 방법론을 제시한다. 저자들은 “관계”라는 추상적 개념을 구체적인 확률 모델로 전환하고, 주어진 쌍 집합 S 에 대해 새로운 쌍 A:B 가 얼마나 유사한 관계를 맺는지를 정량화하고 순위화하는 프레임워크를 설계한다.
1. **문제 정의와 동기**
- 전통적인 아날로지 문제는 “A:B 와 C:D 가 같은 관계인가?”를 인간이 판단하는 것이었다. 데이터베이스나 네트워크에서는 수천·수만 개의 객체와 관계가 존재하므로, 인간이 직접 판단하기 어렵다.
- 특히 생물학(단백질‑단백질 상호작용)과 정보 검색(웹 페이지 하이퍼링크, 텍스트 코퍼스)에서는 관계가 복합적이며, 관계 자체에 대한 메타 정보(예: 관계 유형 라벨)가 거의 없고, 오직 객체의 특징과 존재 여부만이 주어진다.
2. **베이지안 집합(Bayesian Sets) 재해석**
- 기존 베이지안 집합은 “쿼리 집합 S 과 새로운 객체 X 가 동일한 확률 모델에서 생성될 확률”을 베이지안 팩터 log P(X,S) – log P(X) – log P(S) 로 평가한다.
- 저자들은 이를 “관계 모델”에 적용한다. 즉, S 에 포함된 각 쌍 (A⁽ᵏ⁾,B⁽ᵏ⁾) 을 생성한 잠재 함수 g 과, 후보 쌍 (A,B) 를 생성한 잠재 함수 f 가 동일한 파라미터 Θ 를 공유하는지 여부를 비교한다.
3. **함수 공간 모델링**
- 두 객체 집합 A, B 의 카르테시안 곱 A×B 위에 Φ: A×B→ℝᴷ 라는 피처 매핑을 정의한다. 이 피처는 객체의 속성(예: 단백질 서열, GO 어노테이션, 텍스트 단어 빈도 등)과 관계의 구조적 정보(예: 공동 인접 노드 수)를 포함한다.
- 로지스틱 회귀 모델 P(L=1|X,Θ)=σ(ΘᵀX) 를 사용해 관계 존재 여부 L∈{0,1} 를 예측한다. 파라미터 Θ 는 다변량 정규 사전 N(0,Λ⁻¹) 을 갖는다.
4. **베이지안 팩터 계산**
- 공동가능도 P(X,S) 는 Θ 를 공유하는 사후분포를 적분해 얻으며, 이는 변분 베이지안(Variational Bayes) 혹은 라플라스 근사로 근사한다.
- 독립가능도 P(X)P(S) 는 각각 Θ₁, Θ₂ 라는 독립 파라미터에 대해 적분한다.
- 최종 점수 score(A,B)=log P(A,B|S) – log P(A,B) 는 “같은 관계 모델에 속할 가능성”을 직접 반영한다.
5. **알고리즘 흐름**
- (1) S 에 포함된 모든 쌍에 대해 피처 Xᵢⱼ 계산.
- (2) S 를 이용해 공동 사후 q(Θ) (변분 분포) 추정.
- (3) 후보 쌍 (A,B) 에 대해 동일한 q(Θ) 를 사용해 P(A,B|S) 계산.
- (4) 독립 사후 q₁(Θ₁), q₂(Θ₂) 를 각각 S 와 (A,B) 에 대해 추정하고, 베이지안 팩터를 구한다.
- (5) 점수에 따라 후보 쌍을 내림차순 정렬한다.
6. **실험 및 결과**
- **텍스트/웹 도메인**: 위키피디아 페이지와 하이퍼링크 데이터를 사용해 “유사한 링크 구조”를 찾는 작업을 수행. 제안 방법은 코사인 유사도 기반 베이스라인보다 평균 정밀도(AP) 12% 향상.
- **단백질‑단백질 상호작용**: bioPIXIE 프로젝트에서 제공된 작은 기능적 상호작용 쌍 S (5~10개)만을 입력으로, 전체 인간 단백질 상호작용 네트워크(≈20,000쌍)에서 유사한 기능을 가진 새로운 상호작용을 순위화. 정밀도@10이 0.78로, 기존 코-표현 기반 방법(0.54)과 그래프 기반 커뮤니티 탐지(0.61)를 크게 앞섰다.
- **민감도 분석**: 사전 공분산 Λ 의 스케일을 변화시켜도 순위 안정성이 유지되며, 변분 근사와 라플라스 근사 간 차이는 0.03 이하의 AUC 차이만을 보였다.
7. **논의**
- **장점**: 관계 자체를 모델링함으로써 “객체 간 거리”에 의존하지 않고, 관계 예측에 기여하는 피처만을 자동으로 가중한다. 베이지안 팩터는 불확실성을 정량화하고, 작은 S 에도 강건하게 작동한다.
- **제한점**: 로지스틱 회귀는 선형 결정 경계를 가정하므로 복잡한 비선형 관계(예: 다중 단백질 복합체)에는 한계가 있다. 또한 변분 근사의 정확도는 사후 분포가 거의 정규형일 때만 보장된다.
- **향후 연구**: 딥 신경망 기반 비선형 함수 f,g 를 베이지안 집합에 통합하거나, 그래프 신경망(GNN)으로 직접 링크 구조를 피처화하는 방안이 제시된다.
8. **결론**
- 이 논문은 “관계 유사성”을 확률적 함수 공간에서 정의하고, 베이지안 팩터를 이용해 효율적으로 순위화하는 새로운 프레임워크를 제시한다. 텍스트, 웹, 생물학 등 다양한 도메인에서 실험적으로 검증했으며, 특히 제한된 라벨 데이터만으로도 높은 성능을 달성한다는 점에서 실용적 가치가 크다. 향후 비선형 모델과 대규모 변분 추론을 결합하면 더욱 폭넓은 응용이 가능할 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기