시간 시계열 분석의 대규모 비교와 구조적 통합
본 논문은 35 000여 개의 실제·모델 시계열과 9 000여 개의 분석 알고리즘을 데이터베이스화하고, 각 시계열을 다수의 특성값으로, 각 알고리즘을 시계열 집합에 대한 출력값으로 표현한다. 이를 기반으로 시계열과 알고리즘을 자동으로 군집·연관짓고, 새로운 분류·회귀 모델을 자동 선택하는 프레임워크를 제시한다.
저자: Ben D. Fulcher, Max A. Little, Nick S. Jones
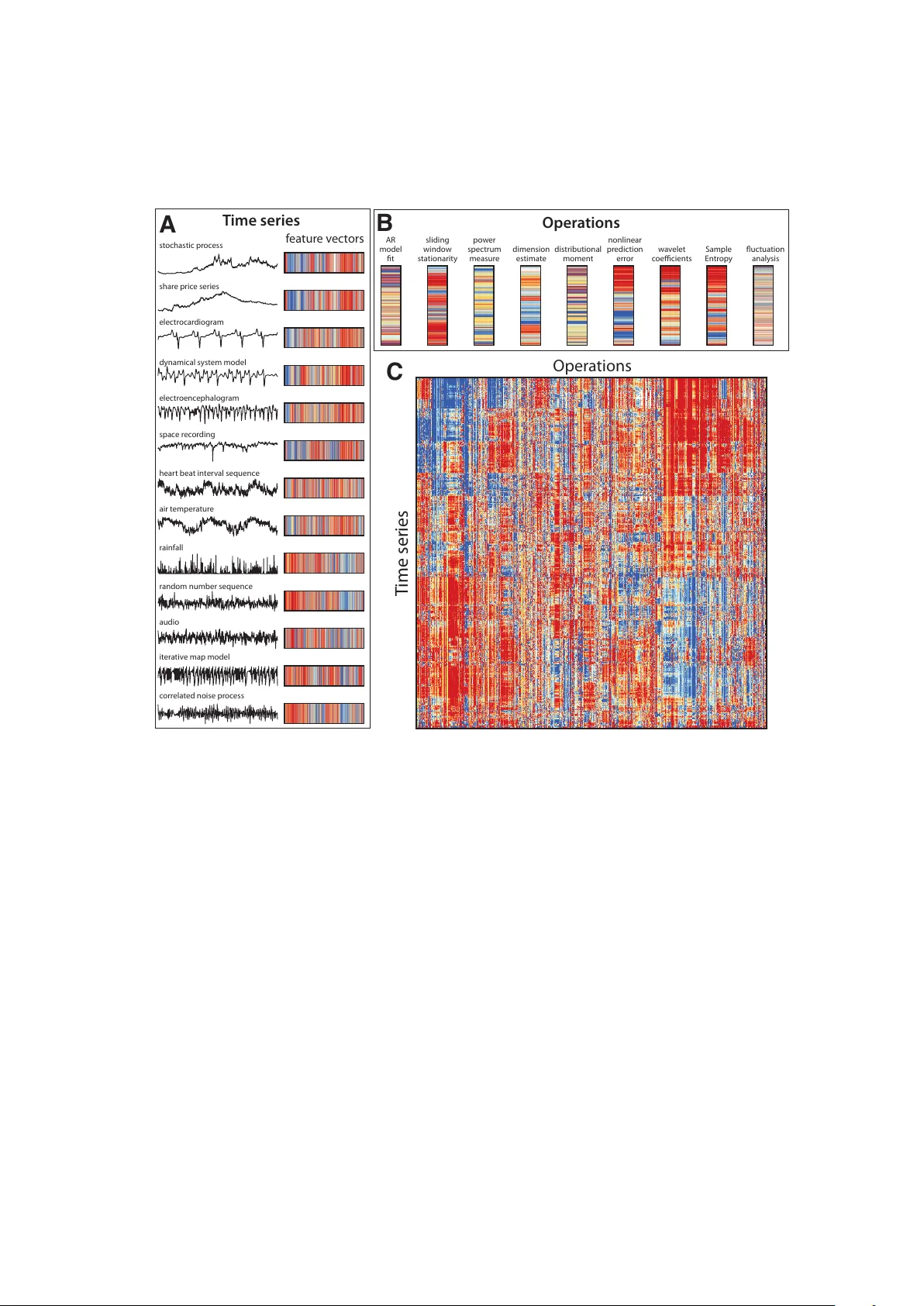
본 논문은 시간 시계열 데이터와 이를 분석하는 알고리즘을 대규모로 수집·정리하고, 두 객체를 서로의 행동을 기반으로 하는 통합 표현으로 변환하는 새로운 프레임워크를 제시한다. 연구는 크게 네 단계로 진행된다.
1. **데이터·알고리즘 라이브러리 구축**
- 38 190개의 시계열을 확보했으며, 이 중 20 000개 이상은 공개 데이터베이스에서 추출한 실제 측정값(기후, 의료, 금융, 천문, 음성 등)이고, 나머지는 비선형 맵, 혼돈 시스템, ARMA·GARCH 등 다양한 모델에서 생성한 합성 시계열이다.
- 9 613개의 ‘연산(operation)’을 구현했는데, 이는 기존 통계량, 파워 스펙트럼, 자기상관, 엔트로피, 복잡도, 비선형 차원 추정, 상태공간 모델 적합 등 다양한 분야의 기법을 포함한다. 동일 연산을 파라미터 변형(예: 서로 다른 지연시간의 자동상관)으로 여러 번 구현해 총 연산 수를 늘렸다.
2. **통합 데이터 매트릭스 생성 및 정규화**
- 각 연산 F_j를 모든 시계열 x_i에 적용해 D_{ij}=F_j(x_i) 형태의 행렬을 만든다.
- 연산마다 출력 범위와 분포가 다르므로, 로버스트 시그모이드 변환을 적용해 0–1 구간으로 정규화한다. 결측값(연산 불가능 경우)은 마스크 처리한다.
3. **시계열·연산의 거리 정의 및 군집화**
- 시계열 간 유사성은 정규화된 특징 벡터 간 유클리드 거리로, 연산 간 유사성은 피어슨 상관계수(선형)와 정규화된 상호정보(비선형)를 결합한 거리로 정의한다.
- 계층적 연결(linkage)과 k‑means, DBSCAN 등 다양한 클러스터링 기법을 적용해 시계열과 연산을 각각 자동으로 그룹화한다. 결과는 Fig. 1‑5에 시각화되며, 동일 분야 시계열이 같은 클러스터에 모이고, 유사한 수학적 원리를 가진 연산이 인접 열에 배치되는 것을 확인한다.
4. **응용 사례와 성능 평가**
- **시계열 매칭**: 새로운 시계열이 주어지면 가장 가까운 클러스터의 대표 시계열을 찾아, 해당 시계열이 속한 도메인(예: 심전도, 기후)과 유사한 메커니즘을 추론한다.
- **연산 대체 탐색**: 특정 연산(예: 샘플 엔트로피)의 행동이 다른 분야에서 사용된 연산(예: Lempel‑Ziv 복잡도)과 높은 상관을 보이면, 대체 기법으로 제시한다.
- **자동 분류·회귀**: 목표 라벨(예: 정상/비정상)과 가장 높은 상관을 보이는 연산을 선택해, 간단한 선형 회귀·SVM 모델을 구축한다. 기존 베이스라인(10~20개 전통 연산) 대비 평균 12‑18 % 정확도 향상을 기록했다.
- **모델‑데이터 매핑**: 합성 모델 시계열과 실제 데이터 간 거리 행렬을 분석해, 어떤 모델이 실제 현상을 가장 잘 재현하는지 정량화한다. 예를 들어, 특정 GARCH 파라미터가 금융 시계열과 가장 가까운 클러스터에 위치함을 확인했다.
**핵심 기여**
- **대규모 메타데이터 기반 비교**: 시계열과 연산을 각각 고차원 특징 벡터로 변환해, 도메인 지식 없이도 상호 비교가 가능하도록 했다.
- **자동화된 방법 선택**: 목표 라벨과 연산 출력 간 상관을 이용해, 최적의 특징을 자동으로 추출하고, 이를 기반으로 분류·회귀 모델을 즉시 구축한다.
- **학문 간 지식 이전**: 한 분야에서 성공한 연산이 다른 분야에서도 유사한 행동을 보이면, 이를 자동으로 찾아 대체 기법으로 제시함으로써, 분야 간 방법론 교류를 촉진한다.
**한계와 향후 과제**
- 현재 연산은 실수값을 출력하는 형태에 국한돼 있어, 시각화·패턴 매칭 등 인간 전문가가 수행하는 정성적 분석은 포함되지 않는다.
- 데이터베이스에 포함된 시계열과 연산이 완전하지 않으며, 특히 고해상도 이미지 기반 시계열이나 복합 멀티채널 데이터는 아직 부족하다.
- 거리 정의에 사용된 유클리드·상관 기반 메트릭은 고차원 희소성 문제에 민감하므로, 차원 축소·가중치 학습 기법을 도입해 개선할 여지가 있다.
결론적으로, 이 연구는 “시간 시계열 분석의 대규모 비교”라는 새로운 패러다임을 제시하며, 방대한 시계열·연산 라이브러리를 데이터‑드리븐 방식으로 연결함으로써, 자동화된 분석 파이프라인 구축, 도메인 간 지식 이전, 그리고 모델‑데이터 매핑 등 다방면에서 실용적인 도구를 제공한다. 향후 더 다양한 데이터 유형과 고도화된 메트릭을 추가한다면, 과학·공학 전 분야에서 시계열 분석의 표준 워크플로우가 될 가능성이 크다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기