확률적 경사 하강을 두 번째 차원 최적화에 가깝게 – 비선형 활성함수 변환
본 논문은 다층 퍼셉트론의 은닉 뉴런에 세 가지 변환(평균 0, 평균 기울기 0, 단위 분산)을 적용해 그래디언트를 자연그라디언트와 뉴턴법에 가까운 형태로 만든다. 이 변환이 피셔 정보 행렬과 헤시안의 비대각 성분을 감소시키고, 대각 성분을 균일하게 만들어 학습 속도를 크게 향상시킴을 이론적 분석과 MNIST 분류·오토인코더 실험을 통해 입증한다. 다만 세 번째 변환(분산 정규화)은 일부 경우에 “죽은 뉴런”을 초래해 최적점이 악화될 수 있다.
저자: Tommi Vatanen, Tapani Raiko, Harri Valpola
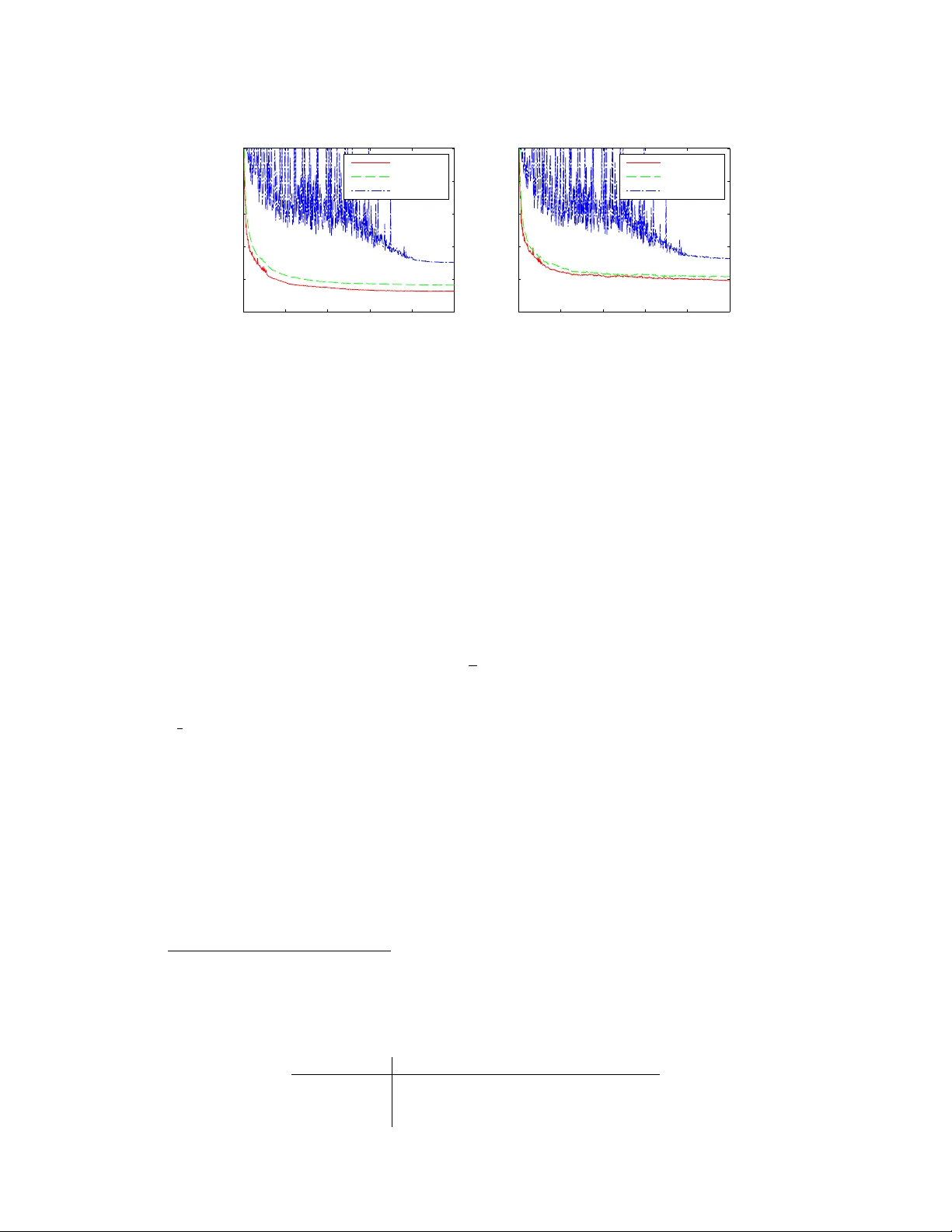
본 논문은 다층 퍼셉트론(MLP) 학습에서 비선형 활성함수의 통계적 특성을 조정함으로써, 확률적 경사 하강법을 자연그라디언트와 뉴턴법 같은 2차 최적화에 가깝게 만드는 방법을 제안한다. 기존 연구에서는 입력을 평균 0으로 중앙화하고, 활성값 자체를 평균 0으로 만드는 변환(활성값 중심화)과 기울기 평균 0으로 만드는 변환(기울기 중심화)을 적용해 학습 속도를 크게 향상시켰다. 이 논문은 그 위에 세 번째 변환인 출력 스케일 정규화(단위 분산)를 추가한다.
### 1. 변환 정의
각 은닉 뉴런 i에 대해 비선형 함수 f_i(b_i x) 를 다음과 같이 재정의한다.
f_i(b_i x) = γ_i
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기