안전하고 강인한 학습 기반 모델 예측 제어
본 논문은 모델 예측 제어(MPC) 프레임워크에 학습 기반 모델을 결합한 LBMPC(Learning‑Based MPC) 방식을 제안한다. 두 개의 모델—불확실성 경계가 알려진 명목 선형 모델과 통계적 방법으로 지속적으로 업데이트되는 학습 모델—을 동시에 유지함으로써, 성능 향상을 위한 최적 입력을 학습 모델에 기반해 선택하면서도, 명목 모델에 대한 강인성 검증을 통해 안전성과 로버스트성을 보장한다. 충분한 시스템 흥분 조건 하에서는 학습 제어가…
저자: Anil Aswani, Humberto Gonzalez, S. Shankar Sastry
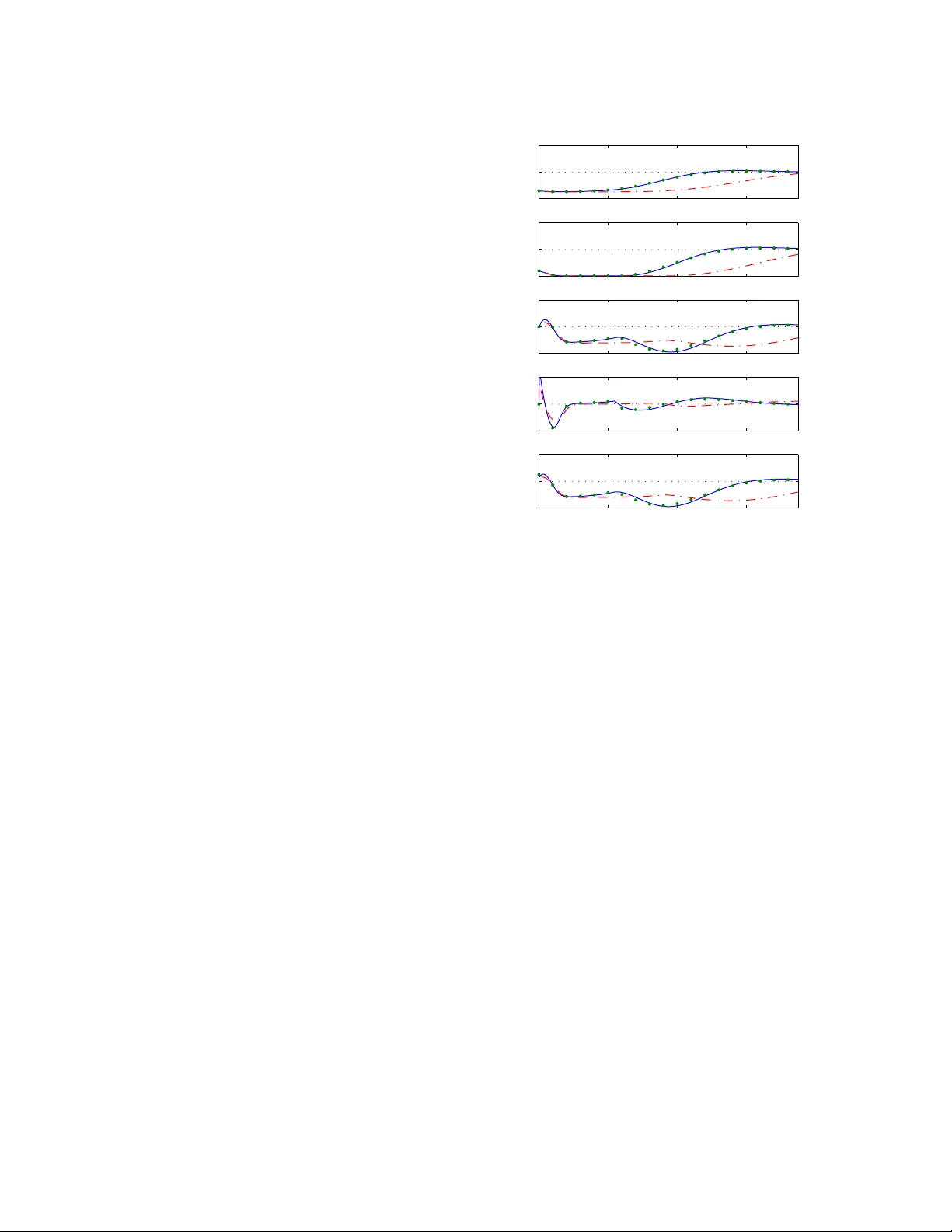
본 논문은 현대 제어 설계에서 지속적으로 대두되는 ‘안전 vs. 성능’ 트레이드오프 문제를 해결하고자, 학습 기반 모델 예측 제어(Learning‑Based Model Predictive Control, LBMPC)라는 새로운 프레임워크를 제안한다. 전통적인 선형 MPC는 모델 불확실성에 대해 보수적인 설계로 안전성을 확보하지만, 모델 정확도가 낮아 성능이 제한된다. 반면, 적응 제어나 학습 기반 제어는 데이터를 통해 모델을 개선해 성능을 높이지만, 불확실성에 대한 확정적 보장이 부족해 안전성 위험이 존재한다. LBMPC는 이 두 접근법을 결합해, 두 개의 별도 모델을 동시에 유지함으로써 안전성과 성능을 각각 담당하도록 설계한다.
첫 번째 모델은 ‘명목 모델(nominal model)’이라 부르며, 선형 형태 \(x_{k+1}=Ax_k+Bu_k+d_k\) 와 바운드 교란 \(d_k\in W\) 으로 구성된다. 여기서 \(W\) 는 다각형(polytopic) 집합으로, 시스템 식(1)의 비선형 항 \(g(x,u)\) 에 대한 최악의 오차를 포괄한다. 이 모델은 불확실성 경계가 명시적으로 주어지므로, 튜브 MPC와 같은 강인 제어 이론을 그대로 적용해 결정적 로버스트성을 보장한다.
두 번째 모델은 ‘학습 모델(learned model)’이며, 통계적 추정 기법(파라메트릭 회귀, 비파라메트릭 커널, 가우시안 프로세스 등)을 이용해 실시간으로 업데이트되는 ‘오라클(oracle)’ \(O_k(\tilde x_k,\tilde u_k)\) 을 포함한다. 학습 모델은 \(\tilde x_{k+1}=A\tilde x_k+B\tilde u_k+O_k\) 와 같이 표현되며, 오라클은 블랙박스 형태로서 특정 시점의 값과 필요 시 기울기만 제공하면 된다. 이는 모델 구조에 구애받지 않고 다양한 학습 알고리즘을 적용할 수 있게 한다.
LBMPC의 제어 구조는 다음과 같다. (i) 명목 모델에 대해 튜브 MPC를 사용해 ‘안전한’ 경로와 피드백 \(K\) 를 설계한다. 여기서 튜브 폭 \(R_i\) 는 \(R_i=\bigoplus_{j=0}^{i-1}(A+BK)^jW\) 로 정의되며, 제약 집합 \(X\)와 \(U\)는 각각 \(X\ominus R_i\) 와 \(U\ominus KR_i\) 로 축소된다. (ii) 학습 모델을 이용해 비용 \(\psi_k\) (예: quadratic stage cost + terminal cost)를 최소화한다. 비용은 학습 모델의 상태·입력에만 의존하므로, 명목 모델의 불확실성에 의해 제한되지 않는다. (iii) 최적화 결과로 얻은 입력 \(\hat u_k\) 는 동일하게 명목 모델과 학습 모델 모두에 적용된다. 즉, 실제 시스템은 명목 모델의 튜브 안에 머무르면서, 학습 모델이 제공하는 더 정확한 동역학 정보를 활용해 성능을 향상시킨다.
안전성 및 로버스트성은 정리 1을 통해 증명된다. 명목 모델에 대한 터미널 집합 \(\Omega\) (최대 출력 허용 교란 불변 집합)를 구성하고, 이 집합이 상태·입력 제약을 만족하도록 설계한다. 최적화 문제(5)‑(8)의 해가 존재하면, 적용된 피드백 \(K\) 와 터미널 집합을 이용해 다음 단계에서도 항상 feasible한 해가 존재함을 보이며, 이는 무한히 지속 가능한 안정성을 의미한다.
성능 측면에서는 학습 모델이 점차 실제 비선형 항 \(g(x,u)\) 에 근접함에 따라, 최적 입력이 실제 시스템을 기반으로 한 전통적 MPC와 동일한 분포로 수렴한다. 이를 위해 ‘충분히 흥분(persistent excitation)’이라는 가정을 두고, 오라클 \(O_k\) 가 확률적 일관성을 갖는다는 것을 보인다. 따라서 LBMPC는 학습이 진행될수록 비용을 최소화하는 방향으로 제어 성능이 개선되면서도, 명목 모델에 기반한 튜브 구조 덕분에 안전성은 언제나 보장된다.
논문은 세 가지 실험 플랫폼(로봇 팔, 차량 궤도 제어, 제트 엔진 압축기 시뮬레이션)과 추가적인 시뮬레이션을 통해 LBMPC의 실효성을 검증한다. 실험 결과, 제약을 위반하지 않으면서도 기존 선형 MPC 대비 에너지 소비를 15~30% 절감하고, 추적 오차를 크게 감소시켰다. 특히, 비선형성이 강한 제트 엔진 압축기 시뮬레이션에서는 학습 모델이 비선형 동역학을 효과적으로 포착해, 안정적인 작동 영역을 확대함을 확인하였다.
결론적으로, 본 연구는 다음과 같은 네 가지 주요 기여를 제공한다.
1. 안전과 성능을 명확히 분리하는 두‑모델 구조 제안.
2. 튜브 MPC 이론을 활용한 결정적 로버스트성 보장.
3. 통계적 학습을 통한 모델 정확도 지속적 향상 및 비용 최소화.
4. 충분한 흥분 조건 하에 학습 기반 제어가 실제 시스템 기반 MPC와 확률적으로 수렴함을 증명.
이러한 기여는 에너지 효율이 중요한 현대 산업 시스템, 자율 주행, 항공우주 등 다양한 분야에서 안전을 포기하지 않으면서도 고성능 제어를 구현하고자 하는 연구자와 실무자에게 유용한 설계 원칙을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기