희소 데이터에서 강인한 위험 모델링을 위한 앙상블 순위 방법
본 논문은 의료 생존 분석에서 관측 수가 적고 차원이 높은 ‘희소’ 데이터를 다루기 위해, 위험 예측 문제를 이분 순위(bipartite ranking) 문제로 전환하고, 새로운 앙상블 알고리즘인 Smooth Rank를 제안한다. Smooth Rank는 각 특성별 단변량 예측기를 비지도적으로 가중합하는 방식으로 강력한 정규화를 구현하고, 커널 기반 밀도 추정과 LOESS 스무딩을 통해 과적합을 방지한다. 10개의 실제 생존 데이터셋에서 기존 C…
저자: Marina Sapir
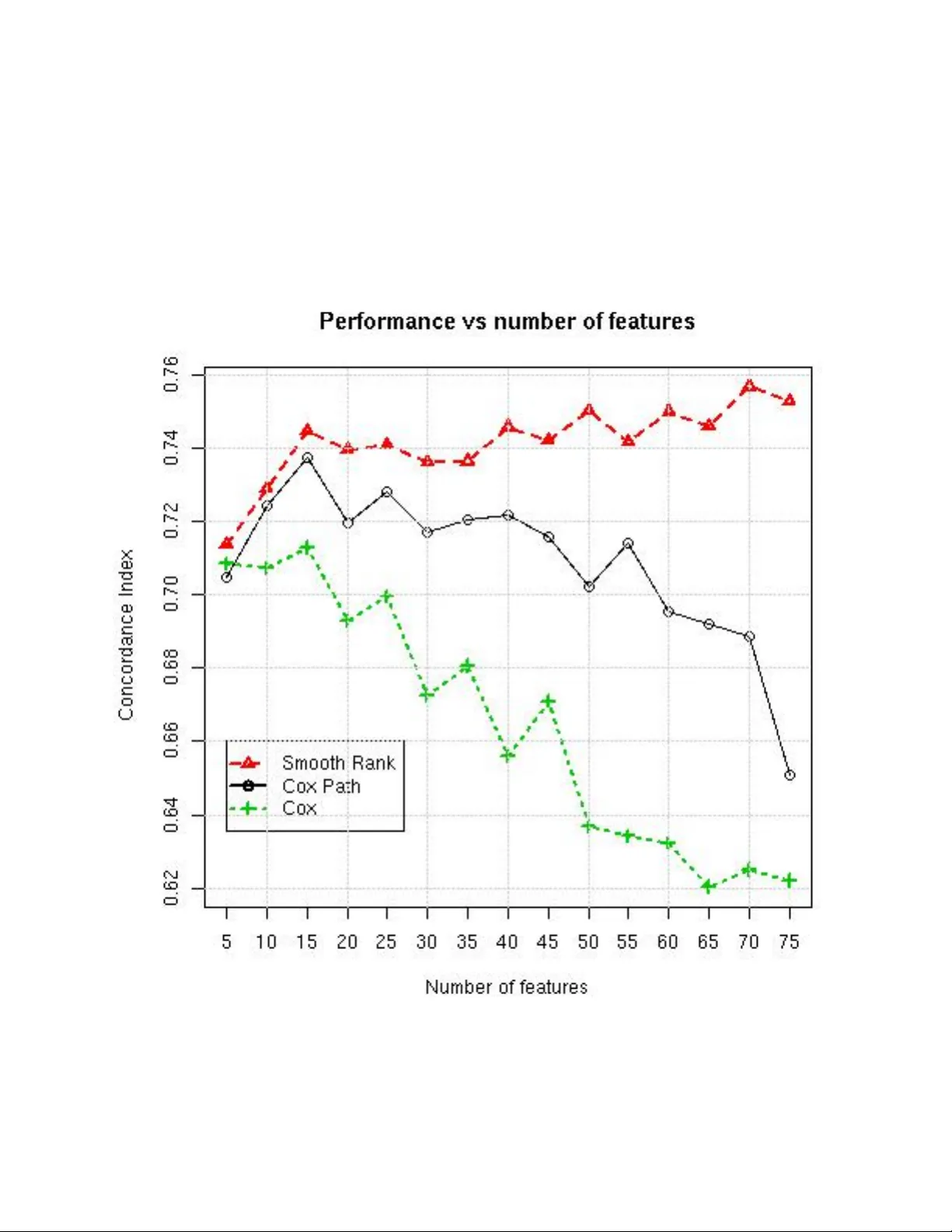
본 논문은 의료 생존 분석에서 흔히 나타나는 ‘희소’ 데이터 문제—관측 수(N)가 적고, 검열(censoring)이 존재하며, 특성 수(M)가 N보다 크게 될 때 발생하는 과적합 위험—를 해결하기 위해 새로운 앙상블 순위 알고리즘인 Smooth Rank를 제안한다.
1. **문제 정의 및 기존 접근법**
- 전통적인 생존 분석은 사건 발생 시간을 직접 모델링하는 Cox 비례위험(Cox PH) 모델에 의존한다. Cox PH는 파라미터 수가 특성 수와 비례하므로 M>N인 경우 적용이 불가능하고, 샘플이 적을 때는 과적합이 심각해진다.
- L1‑정규화된 CoxPath는 변수 선택을 제공하지만, 정규화 강도가 데이터 희소성에 맞게 자동 조정되지 않아 성능 향상이 제한적이다.
2. **위험 정의의 재구성**
- 위험을 “특정 시간 T 이전에 사건이 발생할 확률”로 정의하고, 관측을 ‘조기 사망(early failure)’과 ‘조기 사망이 아닌(no early failure)’ 두 클래스로 이진화한다. 이는 사건 발생 순서를 보존하면서도 생존 시간의 노이즈를 크게 감소시킨다.
3. **Smooth Rank 알고리즘**
- **단변량 밀도 추정**: 각 특성 x_i에 대해 클래스 1과 2의 밀도 g_i1, g_i2를 코사인 커널(512 포인트)로 추정한다.
- **q_i 함수 계산**: q_i(r)= (g_i1(r)−g_i2(r)) / (π_1·g_i1(r)+π_2·g_i2(r)) 로 정의하여, 클래스 비율 차이를 정규화한다. 밀도 합이 일정 임계값 이하인 영역은 제외해 오류 전파를 방지한다.
- **스무딩**: q_i를 LOESS(1차 다항식)로 스무딩하여 e_qi(x)라는 부드러운 단변량 예측기를 만든다.
- **가중치 부여**: 각 e_qi에 대해 C‑index(e_qi, outcome)−0.5 를 가중치 w_i로 설정하고, 최고 가중치 µ와 비교해 µ/3 이하인 경우 0으로 shrinkage한다. 이는 약한 예측기를 자동으로 배제한다.
- **최종 스코어**: F(x)= Σ_i w_i·e_qi(x_i) / Σ_i w_i 로 계산한다. 이는 Naïve Bayes의 가중 투표와 유사하지만, 다변량 최적화 없이 단변량 밀도 기반으로 구성돼 차원의 저주에 강인하다.
4. **실험 설계**
- **실제 데이터**: BMT, Colon, Lung1, Lung2, BC, PBC, Al, Ro02s, Ro03g, Ro03s 등 10개의 생존 데이터셋을 사용. N은 97~929, M은 7~7399 범위이며, 일부는 M>N 상황이다.
- **비교 알고리즘**: 전통적인 Cox PH와 L1‑정규화 CoxPath를 기준선으로 설정.
- **평가 지표**: Concordance index(C‑index)로 모델 성능을 측정.
- **추가 실험**: (a) 훈련 샘플 수를 단계적으로 감소시켜 데이터 희소성이 증가할 때 성능 변화를 관찰, (b) 훈련 샘플 수는 고정하고 특성 수를 증가시켜 M/N 비율이 커지는 상황을 시뮬레이션.
5. **주요 결과**
- 전체 10개 데이터셋 중 8개에서 Smooth Rank가 가장 높은 평균 C‑index를 기록했으며, N/M 비율이 가장 낮은(데이터가 가장 희소한) 두 데이터셋에서는 CoxPath가 약간 앞섰다.
- 훈련 샘플 수가 감소할수록 Cox와 CoxPath의 C‑index는 급격히 떨어지는 반면, Smooth Rank는 완만한 감소를 보이며 과적합이 거의 발생하지 않았다.
- 특성 수를 증가시킬 경우, Cox와 CoxPath는 성능이 급격히 저하되지만 Smooth Rank는 비교적 안정적인 결과를 유지했다. 특히 M≫N인 Al(148 특성, 40 샘플)과 Ro02s(7 집계 특성, 240 샘플)에서 Smooth Rank가 유일하게 적용 가능했다.
6. **의의 및 한계**
- **강점**: (1) 단변량 밀도 기반으로 다변량 최적화가 필요 없으므로 계산 비용이 낮고, 차원의 저주에 강인함, (2) 스무딩과 가중치 shrinkage가 과적합을 효과적으로 억제, (3) 하이퍼파라미터가 거의 없으며, 실무에서 바로 적용 가능.
- **제한점**: 밀도 추정 단계에서 데이터가 극도로 희소하거나 클래스 불균형이 심하면 q_i 계산이 불안정해질 수 있다. 또한 LOESS 스무딩 파라미터를 고정했기 때문에 특정 데이터 구조에 최적화되지 않을 가능성이 있다. 향후 연구에서는 적응형 커널 선택 및 스무딩 파라미터 자동 튜닝을 탐색할 필요가 있다.
7. **결론**
- 위험 예측을 이분 순위 문제로 재구성하고, 각 특성별 단변량 밀도와 스무딩을 결합한 Smooth Rank는 희소하고 고차원인 의료 데이터에서 기존 Cox 기반 방법을 능가한다. 이는 의료 현장에서 제한된 환자 데이터만으로도 신뢰성 있는 위험 모델을 구축할 수 있는 실용적인 대안을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기