적응형 결합 공분산을 이용한 L1 정규화 판별분석
본 논문은 두 클래스의 정규분포 가정을 기반으로, 클래스별 정밀행렬(precision matrix) 차이에 L1 패널티를 적용해 요소별로 선택적으로 결합(pool)하는 L1‑PDA(L1‑Pooled Discriminant Analysis) 모델을 제안한다. λ=0이면 QDA, λ가 충분히 크면 LDA와 동일해지며, λ에 따라 정밀행렬 차이가 희소해지는 경로를 제공한다. ADMM 기반 효율적인 최적화 알고리즘을 제시하고, 모델을 로지스틱 회귀의 …
저자: Noah Simon, Rob Tibshirani
본 논문은 두 클래스에 대한 정규분포 가정 하에, 기존 LDA와 QDA가 각각 갖는 장단점을 보완하는 새로운 판별 분석 기법인 L1‑PDA(L1‑Pooled Discriminant Analysis)를 제안한다. LDA는 모든 클래스가 동일한 공분산 행렬을 공유한다고 가정해 공분산 추정의 분산을 크게 감소시키지만, 실제 데이터에서는 이 가정이 위배되는 경우가 많다. 반면 QDA는 클래스별 공분산을 각각 추정해 편향을 최소화하지만, 표본이 부족할 때 공분산 추정이 불안정해진다.
이를 해결하기 위해 저자는 “대부분의 (i,j) 쌍에 대해 Σ₁⁻¹(i,j)≈Σ₂⁻¹(i,j)”라는 가정을 도입한다. 즉, 두 클래스의 정밀행렬 차이가 희소하다고 가정하고, 차이 행렬 Δ=½(Σ₁⁻¹−Σ₂⁻¹)의 L1 노름을 제한하거나 패널티 형태로 포함한다. 최적화 문제는
max_{μ₁,Σ₁,μ₂,Σ₂} ℓ₁(μ₁,Σ₁)+ℓ₂(μ₂,Σ₂) subject to ‖Σ₁⁻¹−Σ₂⁻¹‖₁≤c, Σ₁,Σ₂≽0
를 convex relaxation하여
min_{Σ₁,Σ₂} −ℓ₁−ℓ₂ + λ‖Σ₁⁻¹−Σ₂⁻¹‖₁
의 형태로 변형한다. 여기서 ℓ_k는 클래스 k의 로그우도이며, μ_k는 샘플 평균으로 고정해도 최적해에 영향을 주지 않는다.
KKT 조건을 전개하면 차이 행렬이 희소하도록 λ가 작용하고, 두 클래스의 공분산 평균 S_pool = (n₁S₁+n₂S₂)/(n₁+n₂) 가 λ와 무관하게 일정함을 확인한다. λ=0이면 QDA 해, λ≥λ_max이면 LDA 해가 되며, λ_max은 n₁n₂‖S₁−S₂‖_∞/(n₁+n₂) 로 정의된다. 따라서 λ를 조절함으로써 LDA와 QDA 사이의 연속적인 경로를 제공한다.
알고리즘 구현은 ADMM(Alternating Direction Method of Multipliers)을 기반으로 한다. 변수 변환 A=Σ₁⁻¹, B=Σ₂⁻¹, C=A−B, 듀얼 변수 Γ를 도입해 다음 네 단계로 반복한다. (1) A 업데이트: 고유값 분해 후 대각 원소에 대한 폐쇄형 식으로 계산, (2) B 업데이트: 동일한 방식, (3) C 업데이트: 소프트-쓰레시팅 연산 S_{λ/ρ}(·) 적용, (4) Γ 업데이트: 듀얼 변수 조정. 각 반복은 O(p³) 복잡도의 고유값 분해가 주된 비용이지만, 수백 차원까지 실용적으로 수행 가능하다. 수렴 기준은 원소별 변화량 또는 원시 목적함수 감소량으로 설정한다.
모델을 역방향 생성 모델(조건부 x|y)에서 전방 로지스틱 모델(p(y|x))로 변환하면,
logit P(y=1|x)=β₀+βᵀx+½ xᵀΓx
가 된다. 여기서 β₀=log(π₁/π₂)+½(μ₂ᵀΣ₂⁻¹μ₂−μ₁ᵀΣ₁⁻¹μ₁), β=Σ₁⁻¹μ₁−Σ₂⁻¹μ₂, Γ=Σ₂⁻¹−Σ₁⁻¹이다. LDA에서는 Γ=0이라 선형 결정 경계, QDA에서는 Γ가 완전 비제로라 전형적인 이차 경계를 만든다. L1‑PDA는 Γ의 비대각 원소를 선택적으로 0으로 만들어 변수 간 상호작용을 희소하게 추정한다. 따라서 고차원 로지스틱 회귀에서 상호작용 선택 문제와 직접 연결된다.
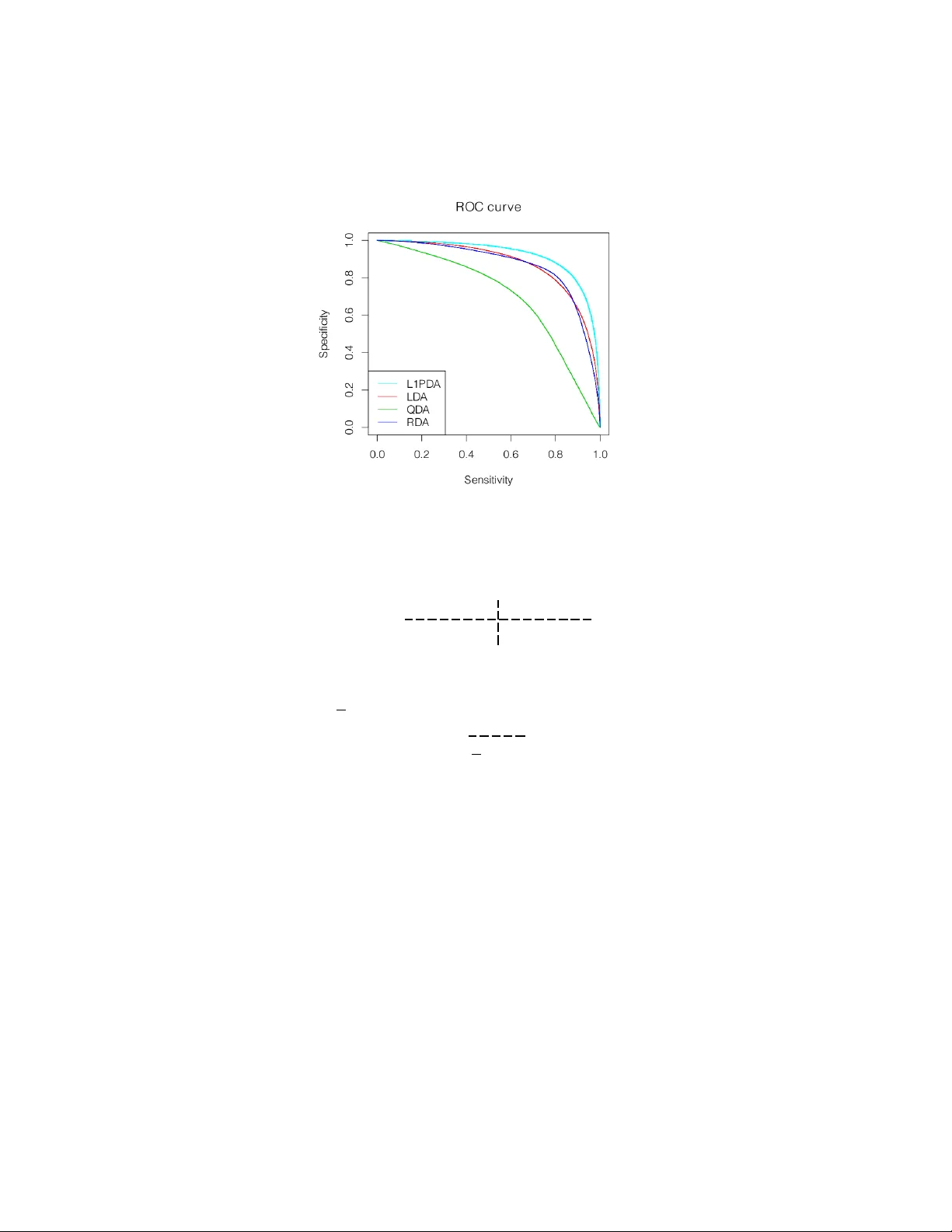
비교 실험에서는 Friedman의 Regularized Discriminant Analysis(RDA)와 Sparse LDA와의 차이를 강조한다. RDA는 공분산을 고유값 축소 방식으로 혼합해 basis‑invariant 특성을 가지지만, L1‑PDA는 특정 변수 공간에서 희소성을 가정해 상호작용을 직접 제어한다. Sparse LDA는 변수 자체를 선택해 선형 결정 규칙을 만든다. 반면 L1‑PDA는 변수는 모두 사용하되, 이차항(상호작용)의 존재 여부만을 조절한다. 실험 결과, p < n₁+n₂인 경우 L1‑PDA가 두 기존 방법보다 분류 정확도와 해석 가능성에서 우수함을 보인다. 또한, S_pool이 full rank이면 λ>0일 때 해가 존재함을 증명해, 표본이 부족한 상황에서도 안정적인 추정이 가능함을 확인한다.
결론적으로, L1‑PDA는 공분산 구조의 부분적 동질성을 활용해 편향‑분산 트레이드오프를 유연하게 조절하고, 상호작용 추정을 통한 해석적 가치를 제공한다. ADMM 기반 최적화는 중간 규모(p 수백) 문제에 실용적이며, λ 경로를 따라 LDA와 QDA 사이의 연속적인 모델을 제공함으로써 사용자가 데이터 특성에 맞는 적절한 복잡도를 선택할 수 있게 한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기