잠금 없는 병렬 SGD Hogwild 알고리즘
Hogwild!는 공유 메모리에서 잠금을 사용하지 않고 다중 코어가 동시에 스토캐스틱 그래디언트 디센트를 수행하도록 설계된 알고리즘이다. 업데이트가 매우 희소한 경우(각 그래디언트가 변수의 작은 부분만 수정) 메모리 충돌이 드물어 거의 최적에 가까운 수렴 속도를 유지한다. 이론적 분석과 실험 결과는 잠금 기반 방법보다 10배 이상 빠른 성능을 보여준다.
저자: Feng Niu, Benjamin Recht, Christopher Re
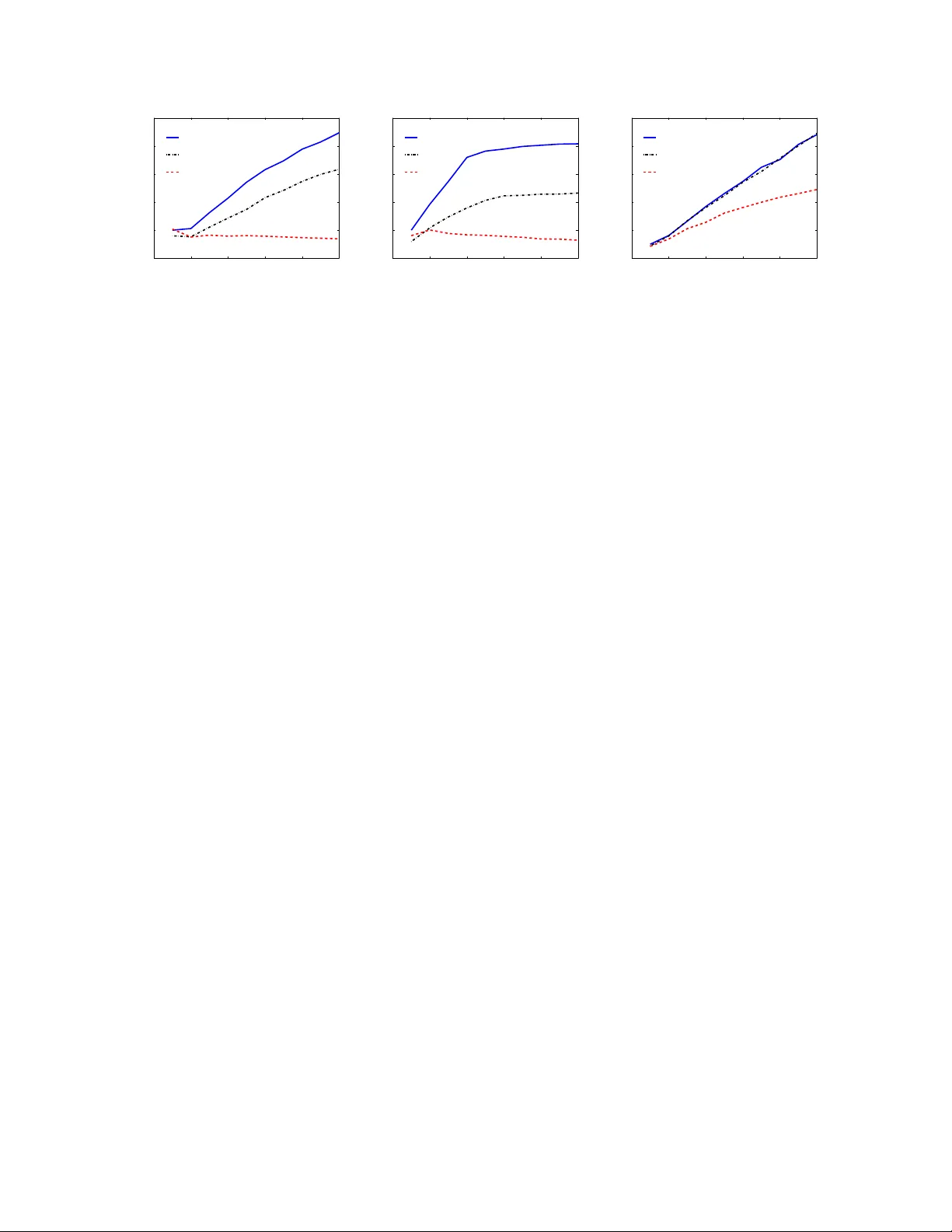
본 논문은 스토캐스틱 그래디언트 디센트(SGD)의 병렬화에 있어 전통적으로 사용되어 온 메모리 락(lock)과 동기화(synchronization) 메커니즘이 성능을 크게 저해한다는 점을 지적한다. 최근 멀티코어 프로세서와 대규모 웹 데이터가 보편화됨에 따라, 락 없이도 효율적인 병렬 SGD가 필요해졌다. 이를 해결하기 위해 저자들은 “Hogwild!”라는 새로운 업데이트 스킴을 제안한다.
Hogwild!는 공유 메모리 모델을 가정하고, p개의 프로세서가 동일한 변수 벡터 x에 동시에 접근한다. 각 프로세서는 다음 절차를 반복한다: (1) 전체 데이터 인덱스 집합 E에서 무작위로 하나의 하이퍼엣지 e를 선택한다. (2) 현재 x_e(즉, e에 포함된 변수들)의 값을 읽고, 해당 부분에 대한 그래디언트 G_e(x)를 계산한다. (3) e에 포함된 모든 변수 v에 대해 원자적 스칼라 업데이트 x_v←x_v−γ·b_v^T G_e(x) 를 수행한다. 여기서 원자적 연산은 현대 CPU의 compare‑and‑swap 혹은 GPU의 단일 원자적 명령으로 구현 가능하며, 별도의 락 구조가 필요하지 않다.
핵심 아이디어는 “희소성(sparsity)”이다. 논문은 최적화 문제를 f(x)=∑_{e∈E} f_e(x_e) 형태로 정의하고, 각 f_e가 변수의 작은 부분 집합 x_e에만 의존한다는 가정을 둔다. 이를 그래프 G=(V,E)로 시각화하면, V는 변수 인덱스, E는 각 f_e가 관여하는 변수 집합이다. Ω=max_{e∈E}|e| (하이퍼엣지 크기), Δ=max_{v∈V} |{e∈E: v∈e}|/|E| (한 변수에 연결된 엣지 비율), ρ= max_{e∈E} |{e'∈E: e'∩e=∅}|/|E| (엣지 간 교차 비율) 로 정의한다. Ω,Δ,ρ가 작을수록 업데이트 충돌이 드물어 잠금 없이도 정확한 수렴이 가능하다.
대표적인 적용 사례로는 (a) 희소 SVM: 각 학습 샘플이 고차원 피처 중 극소수만 비제로이며, f_e는 힌지 손실과 정규화 항으로 구성된다. (b) 행렬 완성(Matrix Completion): 관측된 (u,v) 쌍에 대해 L_u·R_v^T−Z_{uv} 제곱 오차를 최소화하는 문제이며, 각 관측은 두 행/열 벡터만 업데이트한다. (c) 그래프 컷(Graph Cuts): 변수는 각 노드의 라벨 확률벡터이며, 비용은 인접 노드 간 차이의 L1 norm으로 정의된다. 이들 모두 Ω가 2~10 수준, Δ와 ρ는 O(1/n) 정도로 매우 희소하다.
이론적 분석은 Nemirovski et al.의 강한 볼록성 및 Lipschitz 연속성 가정을 차용한다. 함수 f는 강한 볼록성 계수 c와 Lipschitz 상수 L을 갖으며, 각 부분 함수 f_e의 그래디언트 노름은 M으로 유계한다. 업데이트 지연 τ (다른 프로세서가 최신 값을 읽기 전에 발생할 수 있는 최대 스텝 차이)를 고려하여, 학습률 γ를
γ = θ·c / (2·L·M²·Ω·(1+6·ρ·τ+4·τ²·Ω·Δ)^{1/2})
와 같이 설정한다(θ∈(0,1), θ는 상수). Proposition 4.1에 따르면, τ가 Ω·Δ·√ρ·n^{1/4} 이하이면, 즉 프로세서 수 p가 n^{1/4}보다 작을 경우, 수렴 속도는 단일 스레드 SGD와 거의 동일하게 O(1/k) 수준을 유지한다. 구체적으로 k번째 업데이트 후 기대 손실 차이 E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기