복잡도와 상관감쇠 사이의 구조학습 트레이드오프
이 논문은 이진 마코프 랜덤 필드인 이징 모델의 구조를 학습할 때, 알고리즘의 계산 복잡도와 샘플 복잡도 사이에 존재하는 근본적인 트레이드오프를 분석한다. 특히, 상관감쇠가 약해지는(즉, 장거리 상관이 강해지는) 상황에서 저복잡도 알고리즘이 실패하거나 샘플 수가 그래프 크기에 비례해 급증한다는 사실을 구체적인 그래프 예시와 이론적 경계값을 통해 보여준다.
저자: Jose Bento, Andrea Montanari
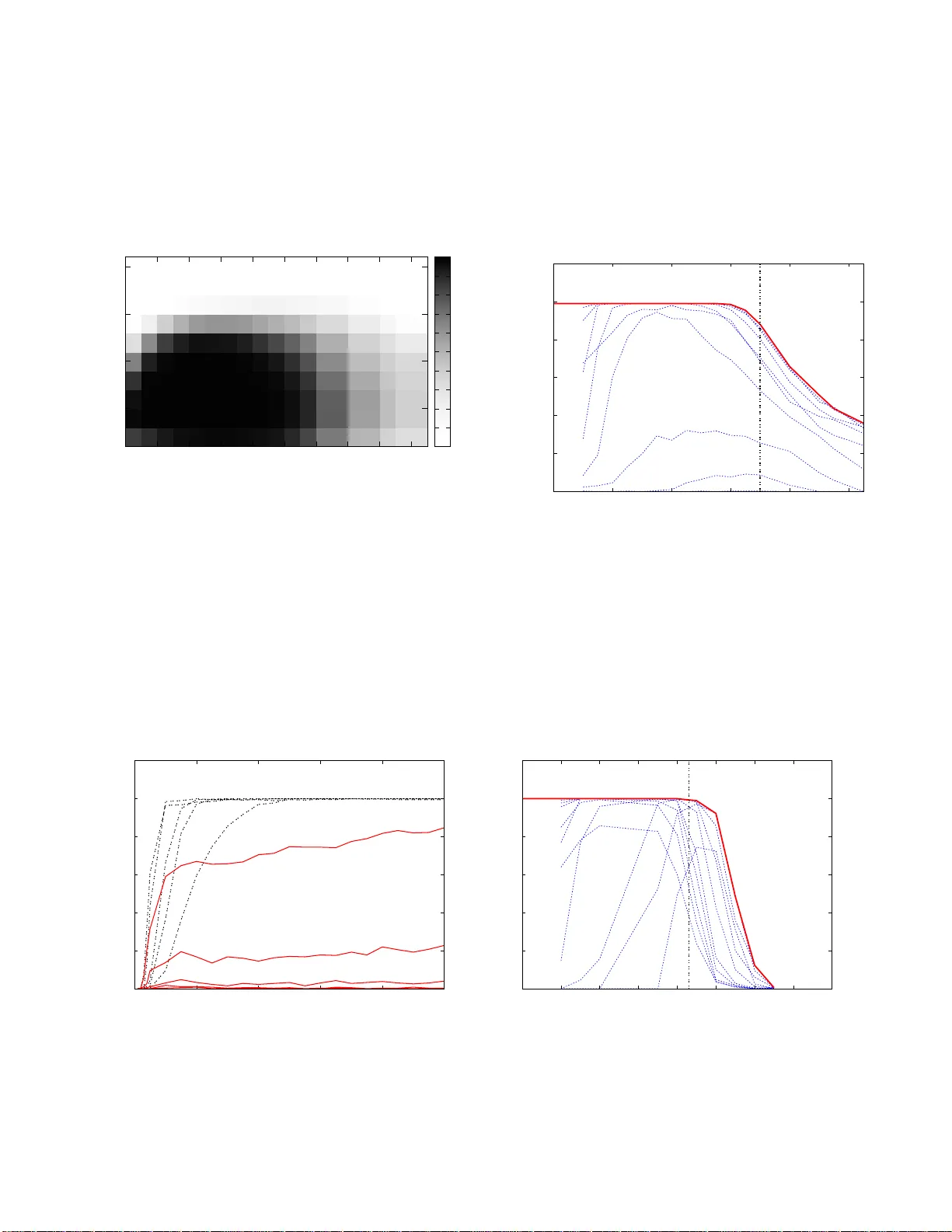
본 논문은 이징 모델의 구조학습 문제를 “샘플 복잡도”와 “계산 복잡도”라는 두 축으로 바라보고, 이 두 축 사이에 존재하는 근본적인 트레이드오프를 정량적으로 분석한다. 이징 모델 µ_{G,θ}(x)=Z^{-1}exp(θ∑_{(i,j)∈E}x_i x_j) 은 파라미터 θ와 그래프 G의 구조에 따라 변수들 사이에 복잡한 상관을 형성한다. 저자는 먼저 이 모델이 지수족(expontial family)이라는 점에서, 충분히 많은 샘플과 무제한 계산 자원을 가정하면 언제든지 정확히 복구 가능함을 상기한다. 그러나 현실적인 제한 하에서는 어떤 (G,θ) 쌍에 대해 저복잡도 알고리즘이 성공할 수 있는지, 혹은 샘플 수가 그래프 크기에 비례해야 하는지를 규명하고자 한다.
논문의 핵심 아이디어는 “상관감쇠”라는 물리적 현상을 복구 가능성의 지표로 삼는 것이다. 이징 모델에서 상관감쇠는 두 변수 사이의 조건부 독립성이 거리와 어떻게 감소하는지를 의미한다. 이와 관련된 이론적 임계값으로 “유니크니스 임계값” θ_{uniq}(Δ)=atanh(1/(Δ−1)) 를 도입한다. θ<θ_{uniq}이면 Gibbs 샘플링이 빠르게 혼합하고, 멀리 떨어진 변수들은 거의 독립에 가깝다. 반대로 θ>θ_{uniq}이면 장거리 상관이 지속되어 변수들 간의 의존성이 강해진다.
이를 바탕으로 저자는 세 가지 대표적인 구조학습 알고리즘을 분석한다.
1. **단순 임계값(Thresholding) 알고리즘**
- 입력: 샘플 {x^{(ℓ)}}_{ℓ=1}^n, 임계값 τ.
- 절차: 모든 (i,j) 쌍에 대해 경험적 상관 C_{ij}= (1/n)∑_ℓ x_i^{(ℓ)}x_j^{(ℓ)} 를 계산하고, C_{ij}≥τ이면 엣지 (i,j)를 추가한다.
- 복잡도: O(p²n) (상관 행렬 계산).
- 이론적 결과: 트리 구조에서는 τ=(tanhθ+tanh²θ)/2 로 설정하면 n=O(log p) 로 정확히 복구 가능. 일반적인 최대 차수 Δ 그래프에서는 θ
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기