다중 회귀에서 양의 수축 및 사전 검정 추정법: 몬테카를로 연구와 실증 적용
본 논문은 회귀 모델에서 일부 공변량이 실제로는 기여하지 않을 가능성을 사전 정보로 활용하고, 이를 검정(pre‑test)하거나 양의 수축(positive‑shrinkage) 방법으로 결합한 추정량을 제안한다. 제한모형과 완전모형 사이를 자동으로 조정하는 두 추정법의 이론적 특성(편향·위험)과 실험적 성능을 세 개의 실제 데이터와 대규모 몬테카를로 시뮬레이션을 통해 비교하였다. 결과는 양의 수축 추정기가 모델 오-specification에 덜 …
저자: SM Enayetur Raheem, S. Ejaz Ahmed
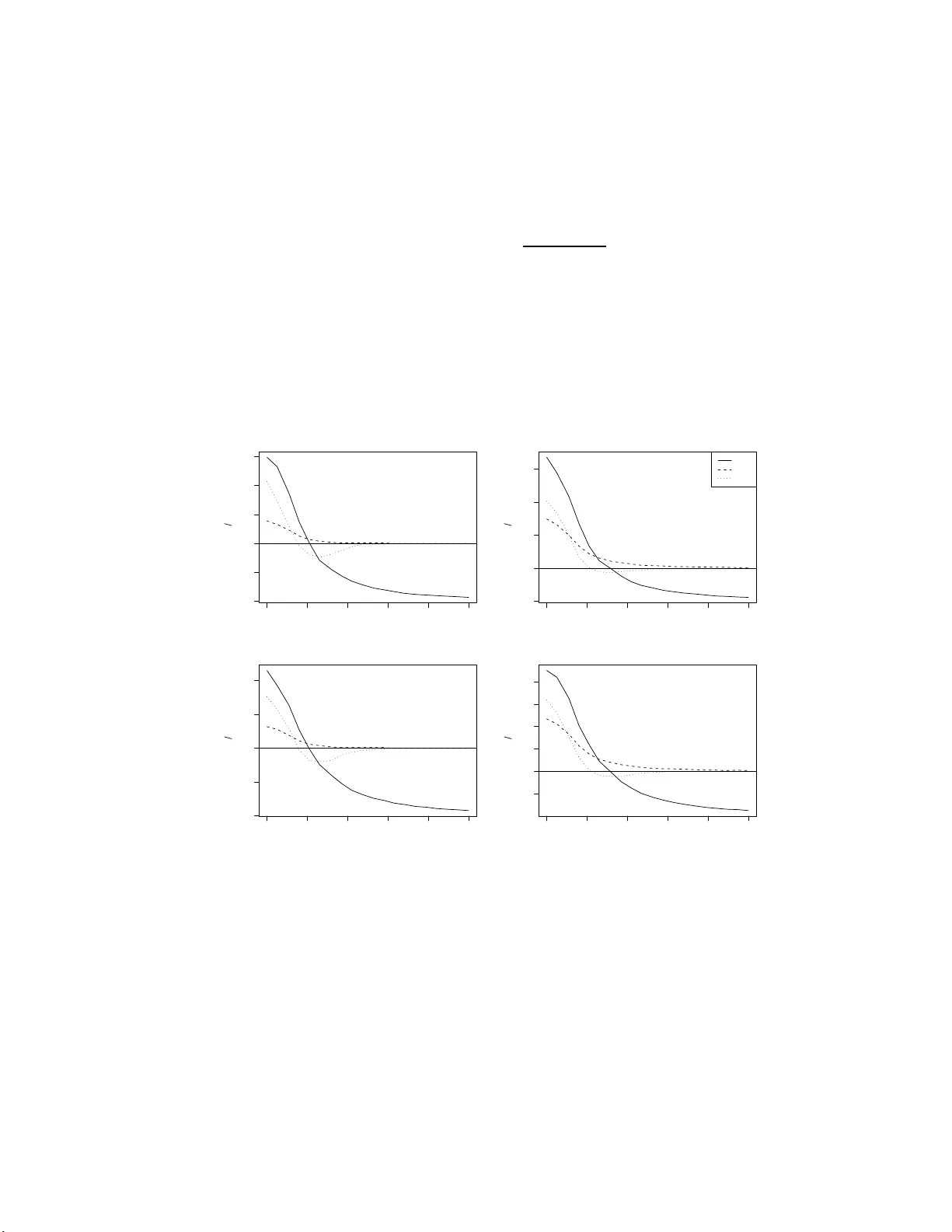
본 연구는 다중 회귀 분석에서 일부 공변량이 실제로는 반응 변수에 기여하지 않을 가능성을 사전 정보로 활용하고, 이를 검정하거나 수축(shrinkage) 방법으로 통합하는 두 가지 추정 전략을 제시한다. 먼저, 회귀식 Y = Xβ + ε 을 고려하고 β를 β₁(주효과)와 β₂(무관 변수)로 분할한다. β₂가 0에 가깝다는 사전 가정은 선형 제한식 Hβ = h 으로 표현되며, 여기서 H는 알려진 행렬, h는 상수벡터이다. 제한식이 참이면 제한최소제곱추정량 β̂_R, 그렇지 않으면 전통적인 최소제곱추정량 β̂_UR을 사용한다.
제한식의 유효성을 검정하기 위해 χ² 검정통계 ψₙ = (Hβ̂_UR − h)′(HCH′)⁻¹(Hβ̂_UR − h)/ŝ_e² 를 정의하고, 유의수준 α 에 따라 제한식이 받아들여지면 β̂_R, 받아들여지지 않으면 β̂_UR을 선택한다. 이를 사전 검정(pre‑test) 추정량 β̂_PT₁ = β̂_UR₁ − (β̂_UR₁ − β̂_R₁)·I(ψₙ < c_{n,α}) 으로 공식화한다.
수축 추정량은 Stein‑type 접근법을 차용한다. 기본 형태는 β̂_S₁ = β̂_R₁ + (β̂_UR₁ − β̂_R₁)(1 − κ/ψₙ)/n 이며, 여기서 κ = p₂ − 2 (p₂ ≥ 3)이다. 그러나 (1 − κ/ψₙ) / n 이 음수가 되면 추정량의 부호가 바뀌어 해석이 어려워진다. 이를 해결하기 위해 양의 부분만 취하는 positive‑shrinkage 추정량 β̂_S⁺₁ = β̂_R₁ + (β̂_UR₁ − β̂_R₁)·max{0, 1 − κ/ψₙ}/n 을 제안한다. 이 추정량은 위험 함수(Risk) 관점에서 기존 Stein‑type 추정량보다 우수함을 증명한다(편향·분산 식 제시).
논문은 이론적 결과를 바탕으로 세 개의 실제 데이터에 적용한다. 첫 번째는 전립선 암 PSA 데이터로, 전체 변수와 AIC, BIC, BSS 기반의 하위모형을 구성한다. 교차검증(K‑fold, K = 5, 10)과 5,000회 반복을 통해 평균 예측오차와 표준오차를 계산한다. 결과는 AIC 기반 제한·사전검정 추정량이 가장 낮은 오류를 보였지만, BSS 기반 과소 지정 모델에서는 양의 수축 추정량이 오류를 크게 감소시켜 제한·사전검정보다 우수함을 보여준다. 두 번째 예시는 미국 주(state) 데이터로, 인구, 소득, 문맹률 등 9개의 변수 중 생존율을 예측한다. 여기서도 양의 수축 추정량이 변수 선택 오류가 있을 때 안정적인 예측 성능을 유지한다. 세 번째 예시는 논문에 상세히 제시되지 않았지만, 동일한 절차를 적용한다.
이후 몬테카를로 시뮬레이션을 수행한다. β₂를 0에 가깝게 설정하되, 사전 정보의 정확도(신뢰도)를 다양하게 변형한다. 시뮬레이션 결과는 (1) 사전 검정 추정량은 사전 정보가 정확할 때는 위험이 낮지만, 정보가 부정확하면 위험이 급격히 상승한다; (2) 양의 수축 추정량은 사전 정보의 정확도와 무관하게 위험이 일정 수준 이하로 유지된다. 또한, 샘플 크기가 커질수록 양의 수축 추정량의 위험이 이론적 한계에 수렴함을 확인한다.
마지막으로 논문은 제한식 검정과 수축을 결합한 두 추정법의 장단점을 정리한다. 제한·사전검정 추정량은 사전 정보가 정확히 맞을 때 최적의 효율성을 제공하지만, 정보가 틀리면 과도한 편향을 초래한다. 반면 양의 수축 추정량은 사전 정보가 약하거나 오류가 있을 때도 안정적인 성능을 보이며, 실제 데이터에서도 모델 지정 오류에 강인함을 입증한다. 향후 연구 방향으로는 고차원 상황에서의 LASSO와의 결합, 비정규 오차 구조에 대한 확장, 그리고 베이지안 프레임워크와의 연계가 제시된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기