강인한 커널 밀도 추정
본 논문은 전통적인 커널 밀도 추정(KDE)에 M‑estimation을 결합해, 오염된 샘플에 대해 강인한 비모수 밀도 추정기(RKDE)를 제안한다. RKDE는 재생 커널 힐베르트 공간(RKHS)에서 샘플 평균을 로버스트하게 추정하고, 커널화된 IRWLS 알고리즘으로 효율적으로 계산한다. 대표정리, 영향함수 분석 및 실험을 통해 기존 KDE보다 이상치에 덜 민감함을 입증한다.
저자: JooSeuk Kim, Clayton D. Scott
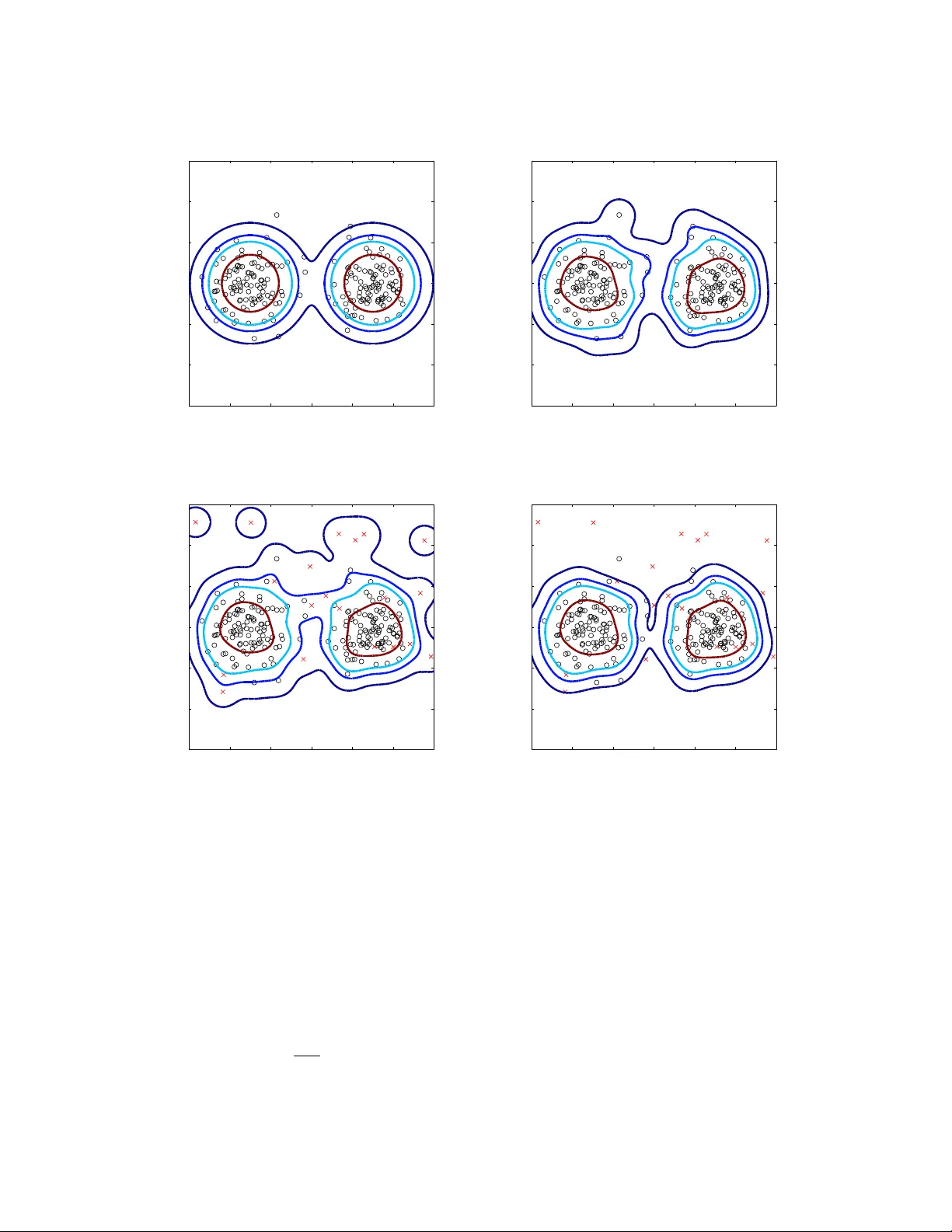
본 논문은 비모수 밀도 추정에서 데이터 오염(이상치) 문제를 해결하기 위해, 전통적인 커널 밀도 추정(KDE)에 M‑estimation 개념을 도입한 강인한 커널 밀도 추정기(Robust Kernel Density Estimator, RKDE)를 제안한다. 저자는 먼저 KDE를 재생 커널 힐베르트 공간(RKHS)에서의 샘플 평균으로 해석한다. 구체적으로, 양의 반정밀도(radial PSD) 커널 kσ(x,xi) 를 사용하면 kσ(x,xi)=⟨Φ(x),Φ(xi)⟩H 로 표현되며, KDE는 Φ(xi)들의 평균 1/n∑iΦ(xi)와 동일하다. 평균은 외부값에 매우 민감하므로, 로버스트하게 추정하기 위해 M‑estimation의 손실 함수 ρ를 도입한다. 목표는 J(g)=1/n∑iρ(‖Φ(xi)−g‖H)를 최소화하는 g∈H 를 찾는 것이다. ρ는 Huber, Hampel 등 ψ=ρ′가 제한된 형태를 사용해 큰 거리의 샘플에 작은 가중치를 부여한다.
수학적으로, Gateaux 미분을 적용하면 δJ(g;h)=−⟨V(g),h⟩H 로 표현되며, 여기서 V(g)=1/n∑iφ(‖Φ(xi)−g‖H)(Φ(xi)−g) 이다. 최적조건 V(g)=0 은 g가 로버스트 평균임을 의미한다. 이를 풀면 g는 가중합 형태 g(x)=∑iwi kσ(x,xi) 로 나타낼 수 있다(대표정리, Theorem 1). 가중치 wi는 φ(‖Φ(xi)−g‖H) 에 비례하고, φ가 감소함을 가정하면 거리‖Φ(xi)−g‖H가 클수록 wi가 작아져 이상치가 자동으로 다운‑웨이트된다. 또한 wi≥0, ∑iwi=1 이므로 g는 정상적인 확률밀도 함수를 만든다.
J가 엄격히 볼록하면 위 조건이 충분조건이 되어 전역 최소점을 보장한다(Theorem 2). 엄격 볼록성은 ρ가 엄격히 볼록하거나, ρ가 볼록하고 커널 매트릭스 K가 양정인 경우에 만족한다(Lemma 2). 따라서 RKDE는 이론적으로 전역 최적해를 갖는다.
알고리즘 측면에서는 전통적인 IRWLS를 커널 트릭과 결합한 KIR‑WLS(Kernelized IRWLS)를 제시한다. 초기 가중치 w(0)i≥0, ∑i w(0)i=1 로 시작해 매 반복마다
f(k)=∑i w(k−1)i Φ(xi)
와
w(k)i=φ(‖Φ(xi)−f(k)‖H) / ∑j φ(‖Φ(xj)−f(k)‖H)
를 업데이트한다. 이 과정은 가중 KDE의 고정점을 찾는 것과 동일하며, 수렴 조건을 이론적으로 증명한다. 실제 구현에서는 ‖Φ(xi)−f(k)‖H 를 커널 값만으로 계산할 수 있어 효율적이다.
강인성 검증을 위해 영향함수(influence function)를 도출한다. RKDE의 영향함수는 ρ의 ψ가 제한된 특성 때문에 제한된 크기를 가지며, 기존 KDE의 무제한 영향함수와 대비된다. 수치 실험을 통해 이상치가 존재할 때 RKDE의 영향함수가 크게 억제되는 것을 확인한다.
실험에서는 2차원 가우시안 혼합, 고차원 네트워크 트래픽 데이터, 여러 공개 데이터셋 등을 사용해 10~20% 수준의 오염을 인위적으로 추가하였다. 결과는 다음과 같다. (1) 밀도 레벨셋 추정에서 RKDE는 오염 전후의 차이가 작아, 실제 밀도 구조를 더 정확히 복원한다. (2) 이상치 탐지(밀도 임계값 기반)에서 RKDE는 높은 검출률과 낮은 오탐률을 기록한다. (3) 변수 커널 밀도 추정(VKDE) 및 기존 로버스트 커널 방법과 비교했을 때, RKDE가 전반적으로 우수한 성능을 보인다.
논문은 또한 기존 연구와의 차별점을 강조한다. 이전의 커널 기반 로버스트 방법은 주로 지도학습(분류, 회귀)에서 사용되었으며, 비모수 밀도 추정에 적용된 사례는 거의 없었다. 또한, 기존의 PSD 커널을 이용한 밀도 추정은 오염에 대한 고려가 없었고, 본 연구는 M‑estimation을 통해 샘플 평균 자체를 로버스트하게 만든 최초의 시도이다.
결론적으로, RKDE는 이론적 보장(대표정리, 볼록성, 수렴성)과 실용적 효율성(커널 트릭 기반 IRWLS) 그리고 강인성을 동시에 제공한다. 이는 비지도 학습에서 데이터 오염이 흔한 실제 문제(예: 네트워크 이상 탐지, 센서 데이터 분석 등)에 바로 적용할 수 있는 강력한 도구가 된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기