잠재 게임 기반 협동 제어를 위한 비합리적 선택 학습 알고리즘
** 본 논문은 잠재 게임(potential game) 형태의 다중 에이전트 협동 제어 문제에 적용할 수 있는 새로운 학습 알고리즘인 Payoff‑based Inhomogeneous Partially Irrational Play(PIPIP)를 제안한다. PIPIP은 기존 DISL 알고리즘에 비합리적 선택 확률을 도입해 낮은 보상의 과거 행동을 가끔 선택하도록 함으로써, 불리한 순수 나쉬 균형에서 탈출하고 잠재 함수의 최대값에 해당하는 최적 …
저자: Tatsuhiko Goto, Takeshi Hatanaka, Masayuki Fujita
**
본 논문은 잠재 게임(potential game)이라는 전략적 게임 모델을 활용해 다중 에이전트 시스템의 협동 제어 문제를 해결하고자 한다. 잠재 게임은 각 에이전트의 로컬 유틸리티 변화가 전체 잠재 함수의 변화와 일치하도록 설계될 수 있어, 로컬 행동 규칙만으로도 전역 목표를 달성하도록 유도한다. 그러나 잠재 게임에는 전역 최적을 나타내는 잠재 함수 최대점 외에도, 로컬 최적에 머무르는 바람직하지 않은 순수 나쉬 균형이 존재할 수 있다. 이러한 비최적 균형에 빠지면 시스템은 목표 달성에 실패한다.
이를 극복하기 위해 저자들은 기존의 Distributed Inhomogeneous Synchronous Learning(DISL) 알고리즘을 기반으로 새로운 학습 규칙인 Payoff‑based Inhomogeneous Partially Irrational Play(PIPIP)를 제안한다. PIPIP의 핵심 아이디어는 에이전트가 일정 확률 ε(t) 로 “비합리적” 행동을 선택하도록 허용하는 것이다. 구체적으로, 각 에이전트는 직전 두 번 선택한 행동 a_i(t‑2), a_i(t‑1) 과 그때 얻은 보상을 기억한다. 일반적인 경우에는 보상이 더 높은 행동을 선택하지만, ε(t) 확률로 보상이 낮았던 과거 행동을 재시도한다. ε(t) 는 시간이 지남에 따라 점차 감소하도록 설계되어, 초기 탐색 단계에서는 비합리적 선택이 활발히 일어나고, 수렴 단계에서는 거의 사라진다.
논문은 이러한 메커니즘을 마코프 연쇄 이론과 저항 트리(resistance tree) 분석을 통해 정형화한다. 먼저, 에이전트들의 집합 행동 공간을 유한 상태 공간 X 로 정의하고, DISL이 생성하는 기본 마코프 연쇄 {P₀^t} 를 고려한다. PIPIP은 ε‑교란(regular perturbation) 형태로, 전이 확률이 1‑ε 일 때는 기존 DISL 규칙을 따르고, ε 일 때는 비합리적 전이로 바뀐다. 정규 교란의 정의에 따라 (A1)~(A3) 조건을 만족함을 보이며, 이에 따라 저항 χ(x→y) 가 정의된다.
다음으로, 잠재 게임의 특성(잠재 함수 φ와 로컬 유틸리티 U_i 사이의 일치 관계)을 이용해, 비합리적 전이가 발생할 경우 잠재 함수 값이 감소하는 경로의 저항이 최소화된다는 점을 증명한다. 특히, 비합리적 선택이 없는 경우(ε=0)에는 시스템이 기존 DISL과 동일하게 순수 나쉬 균형 중 하나에 머무르지만, 비합리적 선택이 존재하면 비최적 균형을 탈출할 확률이 양수이며, ε→0일 때 최적 나쉬 균형(잠재 함수 최대점)으로 수렴하는 확률이 1에 가까워진다. 이는 저항 트리에서 최적 균형 클래스가 최소 스토캐스틱 포텐셜을 가지게 됨을 의미한다.
알고리즘 구현 측면에서 PIPIP은 다음과 같은 장점을 가진다. 첫째, 각 에이전트는 두 개의 과거 행동과 보상만을 저장하면 되므로 메모리 요구량이 매우 작다. 둘째, 실제 보상만을 사용하므로 다른 에이전트의 행동이나 가상 보상 정보를 필요로 하지 않는다. 셋째, 모든 에이전트가 동기식으로 동시에 행동을 선택하므로 실시간 로봇 시스템에 적용하기 용이하다. 넷째, 행동 제약 집합 R_i(a_i) 을 자연스럽게 포함시켜, 물리적 제한이나 안전 구역 등을 고려한 행동 선택이 가능하다.
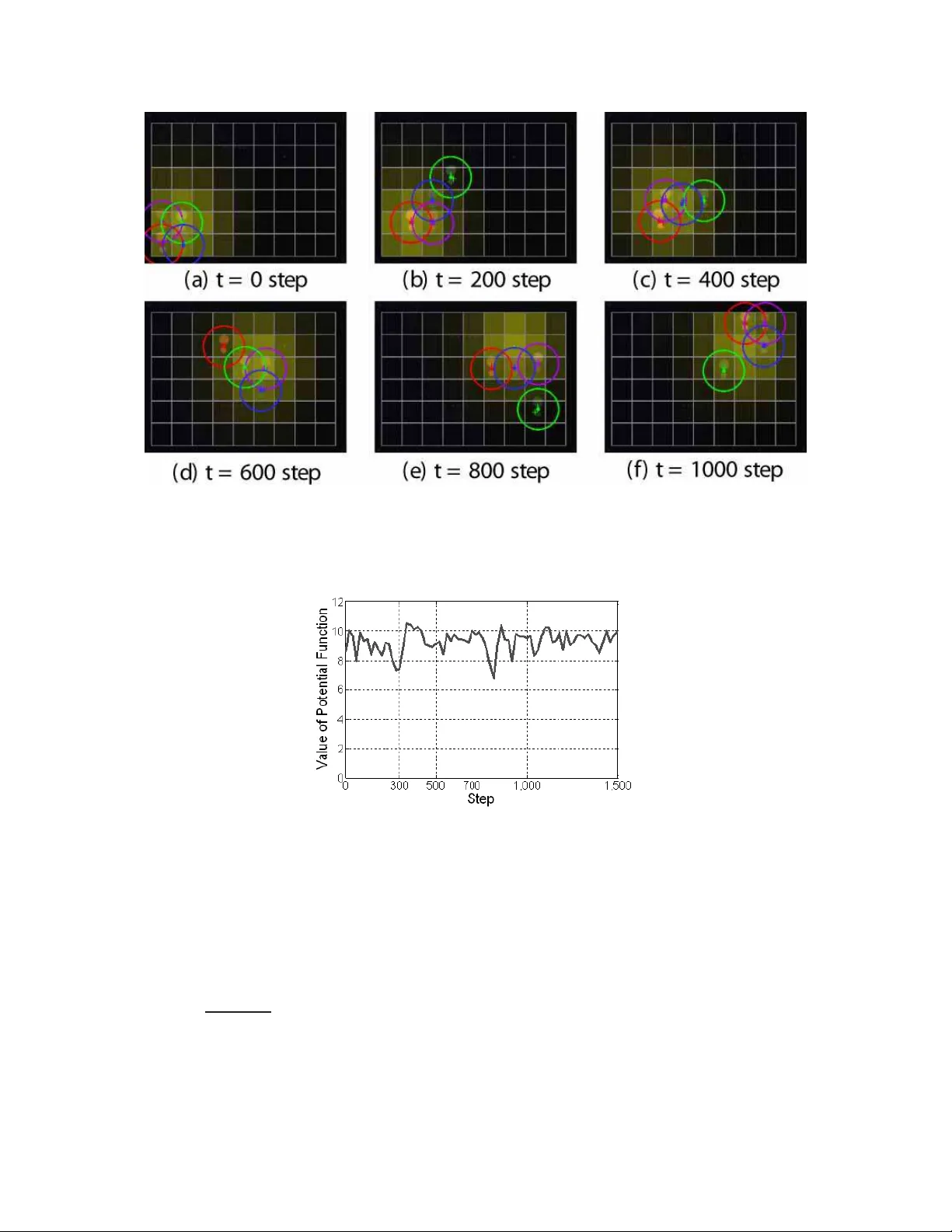
실험에서는 센서 커버리지 문제를 모델링하였다. 미션 공간에 밀도 함수 φ(x) 가 정의되고, 각 센서는 해당 위치에서 얻는 커버리지 보상을 최대화하도록 설계된 유틸리티를 갖는다. 실험 1에서는 고정된 밀도와 장애물을 배치해 비최적 나쉬 균형(센서가 장애물 주변에 과도하게 몰리는 상황)이 발생하도록 만들었다. DISL은 이 상태에 머무르며 전체 커버리지를 개선하지 못했지만, PIPIP은 비합리적 선택을 통해 장애물 주변에서 탈출하고, 센서들을 고르게 배치해 잠재 함수 값을 크게 향상시켰다.
실험 2에서는 밀도 함수가 시간에 따라 이동하는 상황을 설정하였다. PIPIP은 ε(t) 가 감소하면서도 여전히 일정 수준의 탐색을 유지하므로, 밀도 변화에 따라 센서들의 위치를 지속적으로 재조정했다. 결과적으로 센서 군집이 움직이는 고밀도 영역을 추적했으며, 잠재 함수의 실시간 최대값을 거의 따라갔다. 이는 비합리적 선택이 환경 변화에 대한 적응성을 제공한다는 것을 보여준다.
또한 논문은 기존 학습 알고리즘과의 비교를 통해 PIPIP의 차별점을 강조한다. RSAP은 비동기식이며 가상 보상이 필요해 센서 커버리지와 같은 실제 보상 기반 문제에 적용이 어려우며, PLLL은 비합리적 선택을 허용하지만 행동 제약을 명시적으로 다루지 못한다. 반면 PIPIP은 행동 제약을 자연스럽게 포함하고, 확률적 수렴을 통해 최적 나쉬 균형에 도달함을 이론적으로 보장한다.
결론적으로, PIPIP은 (1) 제한된 메모리와 실제 보상만을 이용한 경량 구현, (2) 비합리적 선택을 통한 전역 최적 탈출 메커니즘, (3) 동기식 업데이트와 행동 제약 처리 능력, (4) 확률적 수렴을 통한 최적 나쉬 균형 보장을 제공한다. 이러한 특성은 사전 정보가 부족하거나 환경이 동적으로 변하는 다중 로봇 및 센서 네트워크와 같은 실시간 협동 제어 시스템에 매우 유용하며, 잠재 게임 기반 설계 방법론을 실제 적용 가능한 수준으로 한 단계 끌어올렸다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기