고차원 논리 프로그래밍 기반 의료 전문가 시스템
본 논문은 Prolog의 고차·메타 수준 프로그래밍을 이용해 분류와 연관 규칙 마이닝 엔진을 구현하고, 이를 의료 전문가 시스템에 통합한 설계와 프로토타입을 제시한다. 도출된 규칙은 데이터베이스 트리거와 전문가 시스템 셸에 배치되어 진단 지원 및 무결성 검증에 활용된다.
저자: Nittaya Kerdprasop, Kittisak Kerdprasop
본 논문은 현대 의료기관이 보유한 방대한 전자 데이터베이스를 활용해 새로운 지식을 추출하고, 이를 의료 전문가 시스템에 적용하는 방법을 제안한다. 저자들은 논리 프로그래밍, 특히 Prolog의 고차·메타 수준 프로그래밍을 이용해 분류와 연관 규칙 마이닝 엔진을 구현하고, 이를 전체 시스템 아키텍처에 통합하였다.
1. 서론에서는 지식 자산(knowledge asset)의 개념을 소개하고, 의료 분야에서 암묵적 지식(implicit knowledge)의 발굴 필요성을 강조한다. 기존 데이터베이스 기술은 명시적 지식은 관리하지만, 암묵적 지식은 별도의 마이닝 도구가 필요하다고 주장한다.
2. 사전 지식 섹션에서는 두 가지 핵심 마이닝 기법인 의사결정나무 기반 분류와 Apriori 기반 연관 규칙 마이닝을 수학적으로 정의한다. 분류에서는 정보 이득(Information Gain)을 이용해 최적 속성을 선택하고, 연관 규칙에서는 지원도(support)와 최소 지원 임계값(minS)을 이용해 후보 집합을 축소한다.
3. 시스템 설계(Architecture)에서는 데이터 통합 모듈, 데이터 웨어하우스, 지식 마이닝 모듈, 지식 베이스, 추론·응답 모듈의 5계층 구조를 제시한다. 데이터 통합 단계는 자연어 처리 기반 전처리를 가정하고, 통합된 데이터는 OLAP 도구와 마이닝 엔진이 동시에 접근할 수 있도록 저장된다.
4. 분류 마이닝 엔진은 ID3 알고리즘을 Prolog로 구현한다. 초기화 단계에서 동적 지식베이스를 정리하고, 데이터 속성·양성·음성 사례를 스캔한다. 이후 재귀적으로 노드 카운터를 증가시키며, 각 후보 속성에 대해 Info 값을 계산하고 최소 Info를 갖는 속성을 선택한다. 선택된 속성은 ‘node/2’와 ‘edge/3’ 프레디케이트로 저장되고, 데이터는 해당 노드의 자식으로 분할된다. 최종적으로 완전한 트리가 생성되며, 트리 구조는 Prolog 질의로 확인할 수 있다.
5. 연관 규칙 마이닝 엔진은 고차 Horn 절을 활용한다. ‘maplist’, ‘include’, ‘setof’와 같은 고차 프레디케이트를 이용해 후보 1‑itemset을 생성하고, 데이터베이스 스캔을 통해 지원도를 계산한다. 이후 ‘apriori_loop’ 재귀를 통해 후보 집합을 확장하고, 최소 지원을 만족하는 빈번 패턴을 도출한다.
6. 실행 예시에서는 알레르기 진단을 위한 10건의 환자 데이터를 Prolog 파일 형태로 정의하고, 분류 엔진을 실행해 의사결정나무를 생성한다. 결과 트리는 ‘fever=no’와 ‘swollenGlands=no’가 알레르기 양성(class=yes)인 경우를 나타내는 Horn clause 형태로 요약된다. 연관 규칙 마이닝에서는 최소 지원 50%를 적용해 6개의 빈번 패턴을 도출하고, 예를 들어 ‘fever=yes → class=no’와 같은 규칙을 얻는다.
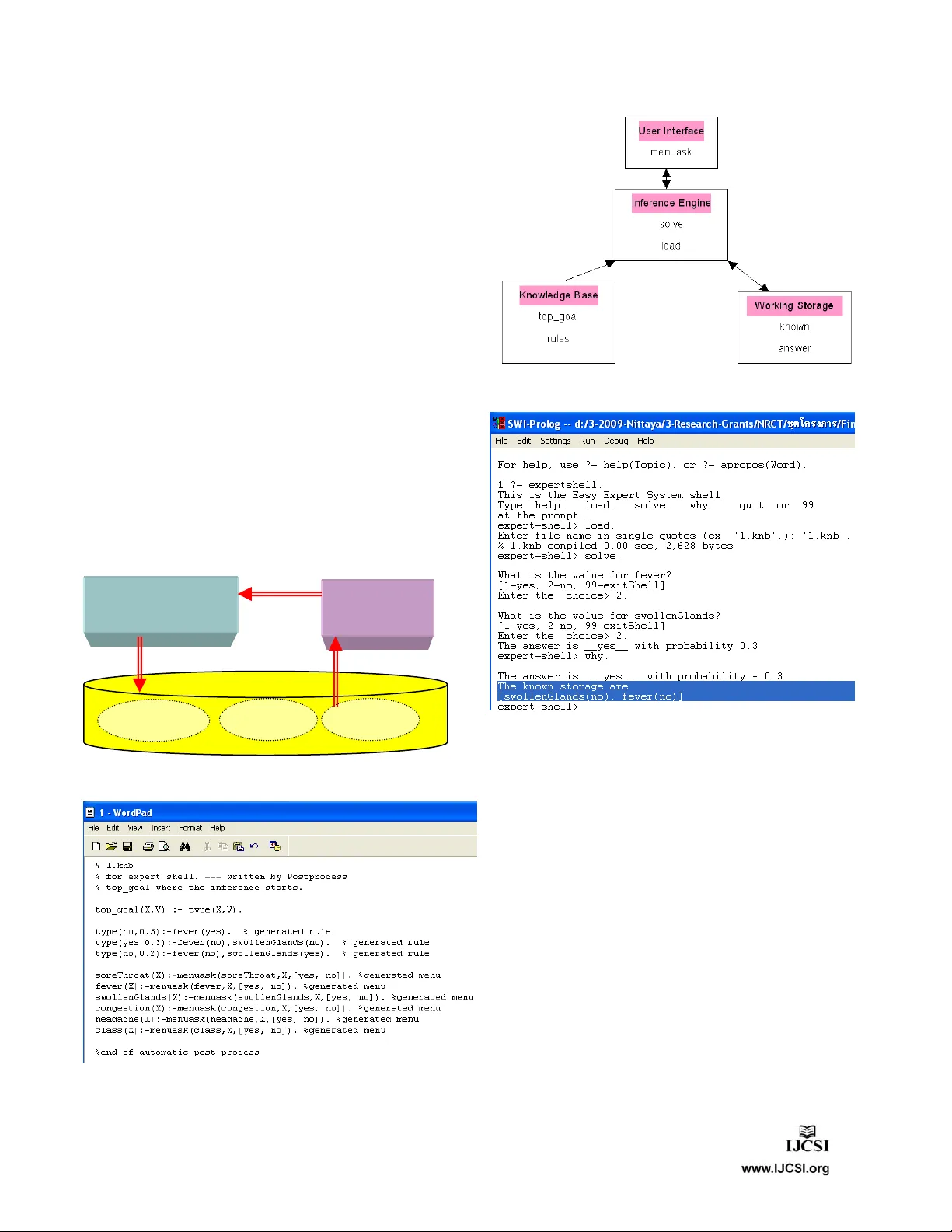
7. 지식 배포(knowledge deployment) 섹션에서는 두 가지 활용 방안을 제시한다. 첫째, 도출된 규칙을 데이터베이스 트리거로 변환해 삽입·수정 시 규칙 위반을 차단한다. 둘째, 규칙을 전문가 시스템 셸의 배경 지식으로 삽입해 사용자가 질의할 때 ‘왜?’(why) 설명을 제공한다. 그림 2·3·4·5는 각각 트리거 구조, 유도된 지식베이스, 전문가 시스템 셸 구조 및 실제 인터페이스 스냅샷을 보여준다.
8. 관련 연구에서는 의료 데이터 마이닝에 머신러닝·통계적 방법을 적용한 기존 연구들을 언급하고, 본 연구가 논리 프로그래밍 기반이라는 차별점을 강조한다.
9. 결론에서는 고차·메타 프로그래밍이 복잡한 지식 집약 시스템을 선언적·간결하게 구현하는 데 유리함을 재확인하고, 향후 대규모 데이터셋에 대한 성능 평가와 자동화된 규칙 검증 메커니즘 구축이 필요함을 제시한다.
전체적으로 논문은 Prolog를 활용한 의료 마이닝 엔진의 설계·구현 과정을 상세히 기술하고, 마이닝 결과를 실시간 데이터 무결성 검사와 전문가 시스템에 재사용하는 실용적인 프레임워크를 제시한다. 다만 실험 규모가 제한적이며, 시스템 통합·성능 검증 부분이 보강될 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기