그리디와 서브모듈러 비율이 이끄는 최적 변수·사전 선택
이 논문은 선형 회귀에서 목표 변수 Z를 예측하기 위해 k개의 변수만을 선택하는 서브셋 선택 문제와, 다수 목표에 대한 사전(dictionary) 선택 문제를 다룬다. 저자는 기존의 코히런스·RIP 기반 이론이 지나치게 강한 가정을 요구하는 반면, “서브모듈러 비율”(submodularity ratio)이라는 새로운 지표를 도입해 그리디 알고리즘(Forward Regression, Orthogonal Matching Pursuit)의 근사 보장…
저자: Abhimanyu Das, David Kempe
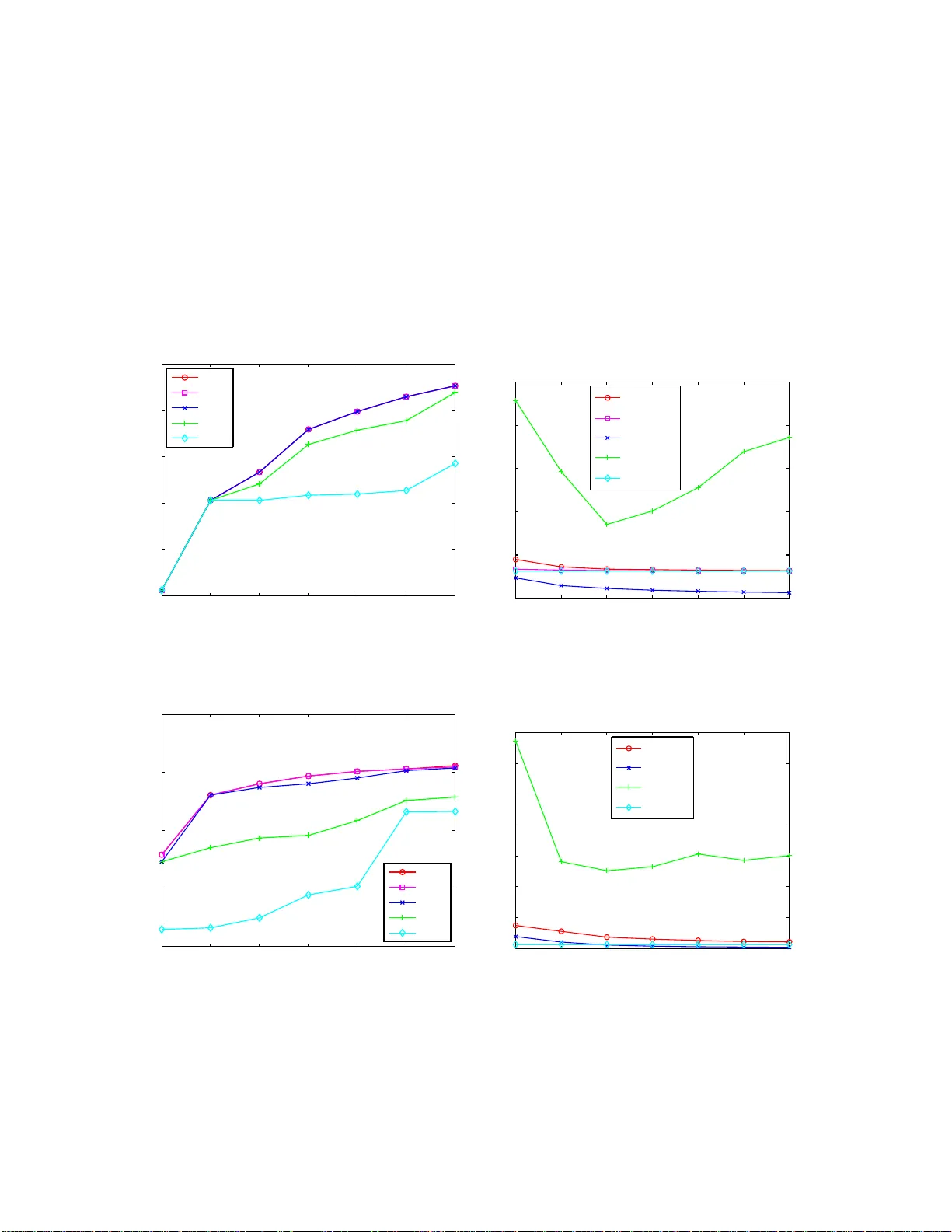
본 논문은 “k개의 변수만을 사용해 목표 변수 Z를 최적 선형 예측하는 서브셋 선택” 문제와, “다수 목표에 대한 사전(dictionary) 선택” 문제를 통합적으로 다룬다. 문제 정의는 공분산 행렬 C와 목표-변수 간 공분산 벡터 b를 이용해 R²(S)=b_SᵀC_S⁻¹b_S 를 최대화하는 집합 함수 f(S)로 표현된다. 이 함수는 일반적으로 비서브모듈러이며, 기존 이론은 변수 간 코히런스 μ가 1/k 이하이거나, 제한등가성(RIP) 혹은 최소 k‑희소 고유값 λ_min(C,k) 가 충분히 큰 경우에만 근사 보장을 제공했다. 그러나 실제 데이터는 높은 상관관계와 거의 특이적인 공분산 구조를 갖는 경우가 많아 이러한 가정은 현실과 괴리된다.
이를 해결하기 위해 저자는 “서브모듈러 비율”(submodularity ratio) γ_{U,k}(f)를 도입한다. γ는 임의의 현재 집합 L과 후보 집합 S에 대해, 개별 원소를 추가했을 때 얻는 marginal gain의 평균이 전체 집합을 한 번에 추가했을 때의 gain에 비해 얼마나 손실되는지를 정량화한다. γ가 1에 가까우면 f는 거의 서브모듈러이며, γ가 0에 가까우면 서브모듈러와 거리가 멀다. 중요한 점은 γ가 최소 k‑희소 고유값 λ_min(C,k) 로부터 하한을 가진다는 사실이다. 즉, λ_min이 0에 가까워도 γ는 양의 값을 유지할 수 있어, 기존 스펙트럴 기반 보정보다 완화된 조건에서 근사 보장을 얻을 수 있다.
논문은 두 가지 대표적인 그리디 알고리즘을 분석한다. 첫 번째는 Forward Regression(FR)으로, 현재 선택 집합 L에 대해 잔차와 가장 높은 상관을 보이는 변수를 순차적으로 추가한다. 두 번째는 Orthogonal Matching Pursuit(OMP)으로, 현재 선택 집합에 직교화된 잔차와 가장 큰 내적을 갖는 변수를 선택한다. 두 알고리즘 모두 서브모듈러 비율 γ와 최소 k‑희소 고유값 λ_min(C,k)를 이용해 다음과 같은 근사 비율을 증명한다.
- FR: f(S_FR) ≥ (1−e^{−γ})·f(S^*)
- OMP: f(S_OMP) ≥ (1−e^{−γ·λ_min(C,k)})·f(S^*)
여기서 S^*는 최적 선택 집합이다. 특히 OMP의 경우 λ_min이 작아도 γ가 충분히 크면 여전히 강력한 보장을 제공한다. 이는 기존 코히런스 기반 보증이 μ≈1/k 이상에서 무용지물이 되는 상황을 극복한다.
다음으로 논문은 “사전 선택” 문제로 확장한다. 여기서는 s개의 목표 Z_j와 n개의 후보 변수 X_i가 주어지고, 최대 d개의 변수로 구성된 사전 D를 선택한다. 각 목표 Z_j에 대해 D에서 k개의 변수를 골라 R²를 최대화하고, 모든 목표에 대한 평균 R²를 최적화한다. 기존 연구(Krause & Cevher)는 근사 서브모듈러 개념을 사용했지만, 보장은 γ·λ_max·(1−1/e) 형태로 매우 느슨했다. 본 논문은 동일한 서브모듈러 비율 프레임워크를 적용해 SDS‑MA(그리디 사전 선택 알고리즘)의 근사 비율을 γ·λ_max·(1−1/e) 로 크게 개선한다. 이는 실험에서 기존 방법보다 현저히 높은 평균 R²를 달성함을 보여준다.
실험에서는 합성 데이터와 두 개의 실제 데이터셋(예: 유전자 발현 데이터와 이미지 피처 데이터)을 사용해 FR, OMP, L1‑relaxation(Lasso) 등을 비교한다. 실험 결과는 다음과 같다. (1) 공분산 행렬이 거의 특이점에 가까워도 서브모듈러 비율 γ가 크게 유지되어 그리디 알고리즘이 높은 R²를 달성한다. (2) γ는 코히런스 μ보다 예측력이 뛰어나며, 특히 μ가 1/k 이상일 때도 γ는 여전히 양의 값을 유지한다. (3) λ_min이 작아도 γ가 충분히 크면 근사 비율이 크게 감소하지 않는다. (4) 사전 선택 실험에서 SDS‑MA가 기존 방법보다 평균 R²가 10~20% 이상 향상된다.
논문의 주요 기여는 네 가지로 요약된다.
1. 서브모듈러 비율이라는 새로운 지표를 도입해 그리디 알고리즘의 성능을 스펙트럴 특성(λ_min)과 연결, 기존 코히런스·RIP 기반 보정보다 약한 가정으로 강력한 근사 보장 제공.
2. Forward Regression과 Orthogonal Matching Pursuit에 대해 각각 1−e^{−γ}와 1−e^{−γ·λ_min} 형태의 멀티플리케이티브 근사 비율을 증명, 특히 OMP는 λ_min이 작아도 γ가 충분히 크면 좋은 성능을 보장.
3. 사전 선택 문제에 동일한 프레임워크 적용, 기존 SDS‑MA 보증을 크게 개선하고 실험적으로도 우수한 성능 입증.
4. 실험을 통해 서브모듈러 비율이 실제 성능을 가장 잘 예측한다는 실증적 증거 제공, 이는 고상관·거의 특이적인 데이터에서도 그리디 기반 변수 선택이 실용적임을 시사한다.
결론적으로, 이 연구는 서브모듈러 비율을 통해 그리디 알고리즘의 이론적 근거를 크게 확장하고, 실제 데이터에서도 높은 예측 정확도를 달성할 수 있음을 보여준다. 앞으로 서브모듈러 비율을 사전에 추정하거나, 이를 활용한 알고리즘 설계가 고차원·고상관 데이터 분석에 중요한 도구가 될 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기