BFS 샘플링 편향의 정확한 분석과 실용적인 보정 방법
본 논문은 무작위 그래프 모델 RG(pₖ) 위에서 BFS(및 유사 탐색 기법) 샘플링이 고도 노드에 편향되는 현상을 정량적으로 분석하고, 샘플링 비율 f 에 따른 기대도수 분포 qₖ 를 도출한다. 이를 기반으로 f 와 관측된 샘플만으로 편향을 보정하는 실용적인 절차를 제시하며, 다양한 인터넷 토폴로지와 Facebook·Orkut 대규모 실험에서 높은 정확성을 확인한다. 또한 편향이 없는 대안 방법들을 비교 평가했으나, 분산이 커 실용성이 낮음을…
저자: Maciej Kurant, Athina Markopoulou, Patrick Thiran
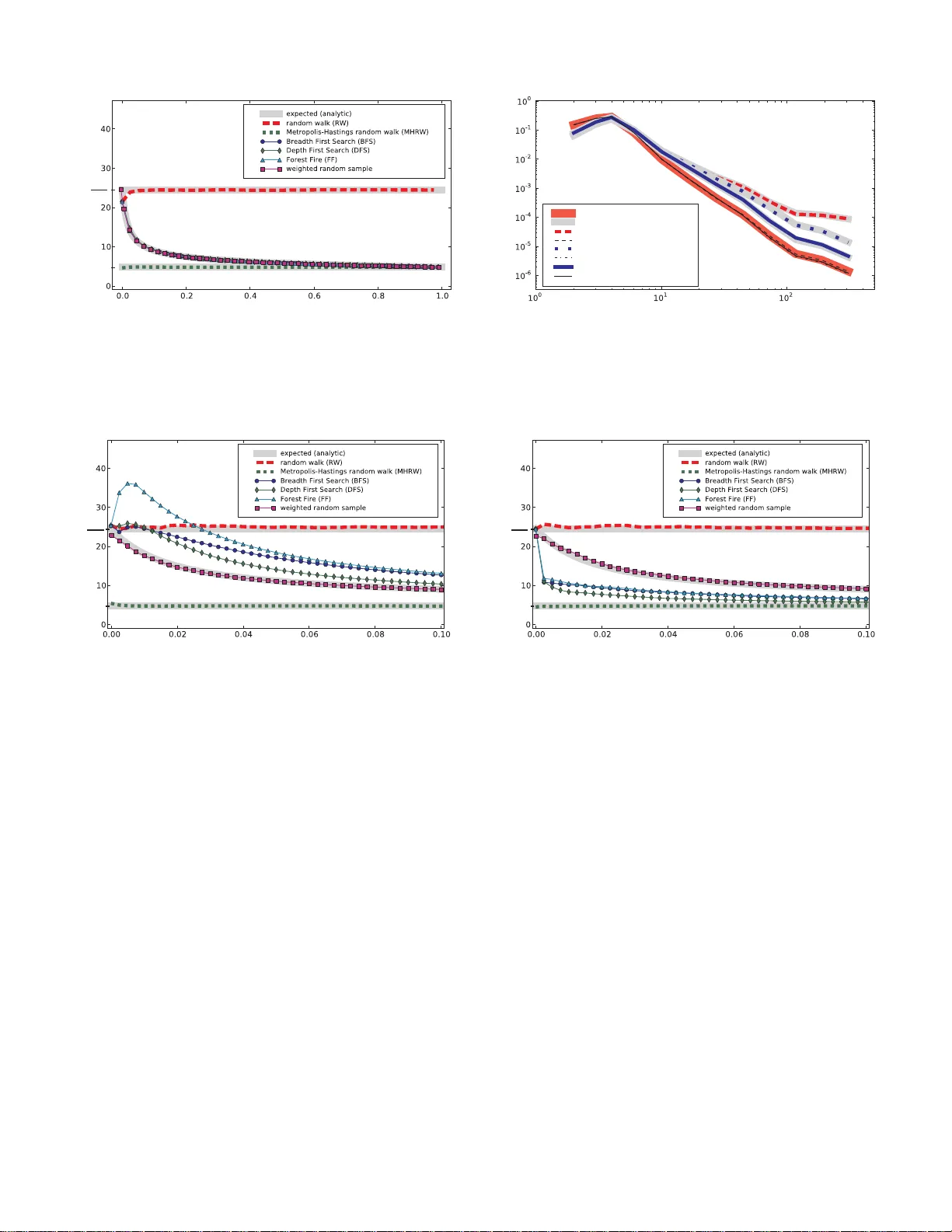
본 논문은 인터넷 규모의 미지 그래프를 탐색하기 위해 널리 사용되는 BFS(폭넓이 우선 탐색) 샘플링이 고도(노드 차수)가 큰 노드에 편향되는 현상을 정량적으로 분석하고, 이를 보정하기 위한 실용적인 방법을 제시한다. 연구는 크게 네 부분으로 구성된다.
첫 번째 부분에서는 기존 연구에서 관찰된 BFS의 고도 편향을 재조명한다. BFS는 그래프 전체를 탐색하지 않고 일정 비율 f 만큼만 샘플링할 경우, 초기 단계에서 고도 노드가 더 많이 발견되는 경향이 있다. 저자들은 이 현상이 단순히 “무작위 워크와 유사한” 편향이 아니라, 탐색 과정 자체가 ‘크기 비례 추출(Probability Proportional to Size without Replacement, PPSWOR)’이라는 통계적 메커니즘에 기반한다는 점을 강조한다.
두 번째 부분에서는 이론적 모델링을 수행한다. 임의 그래프 모델 RG(pₖ) (주어진 차수 분포 pₖ 를 갖는 구성 모델)를 가정하고, BFS(및 DFS, Forest Fire, Snowball, RDS)가 진행되는 동안 각 노드가 처음 발견될 확률을 차수 k 에 대한 함수로 전개한다. 이를 통해 샘플링 비율 f 에 따라 기대되는 샘플 차수 분포 qₖ(f) 를 정확히 도출한다. 주요 결과는 다음과 같다. (1) f 가 매우 작을 때 qₖ(f) 는 k·pₖ 에 비례해 고도 노드가 과대표집되는 RW와 동일한 편향을 보인다. (2) f 가 증가함에 따라 편향은 점진적으로 감소하고, f=1 (전체 탐색)에서는 편향이 사라져 qₖ=pₖ 가 된다. (3) BFS뿐 아니라 DFS, Forest Fire, Snowball Sampling, RDS 모두 동일한 qₖ(f) 함수를 공유한다는 점을 증명한다. 이는 기존에 각 기법마다 다른 편향을 가정했던 선행 연구와 차별화되는 중요한 발견이다.
세 번째 부분에서는 위 이론을 바탕으로 실용적인 편향 보정 절차를 제시한다. 입력으로는 (i) 관측된 BFS 샘플의 차수 빈도 \hat{qₖ} 와 (ii) 전체 샘플 비율 f 가 주어진다. 먼저, 도출된 qₖ(f) 식의 역함수를 이용해 원래 차수 분포 pₖ 를 추정한다. 그런 다음, 임의 함수 x(v) (예: 노드 속성, 평균 차수 등)의 전체 그래프 평균을 추정하기 위해, 샘플 내 각 노드에 pₖ 추정값에 기반한 가중치를 부여해 가중 평균을 계산한다. 이 방법은 그래프가 RG(pₖ) 와 정확히 일치하지 않더라도, 실험적으로 높은 정확도를 보인다. 저자들은 이 절차를 파이썬 구현으로 공개하고, 다양한 인터넷 토폴로지(예: AS‑level, 웹 그래프, P2P 네트워크)와 대규모 소셜 네트워크(Facebook, Orkut)에서 적용해 평균 차수, 클러스터링 계수, 경로 길이 등 여러 지표를 원본 값에 근접하게 복원함을 입증한다.
네 번째 부분에서는 “완전 무편향” 대안 방법들을 소개하고 비교한다. 첫 번째 대안은 샘플링 과정 자체를 시뮬레이션하거나 베이지안 추정으로 qₖ 를 직접 구하는 방법이다. 두 번째는 기존 사회과학 분야에서 사용되는 RDS 보정 기법을 일반화한 것으로, 무작위 워크와 동일한 가정을 두지만, 샘플 비율 f 가 커질수록 시스템적 편향이 발생한다는 점을 지적한다. 실험 결과, 이러한 대안들은 편향은 없지만 추정값의 분산이 크게 증가해 신뢰구간이 넓어 실용성이 떨어진다.
마지막으로 논문은 연구 범위와 한계를 논의한다. 이론적 결과는 RG(pₖ) 모델에 엄밀히 적용되지만, 실제 네트워크는 동적 변화, 동질성, 높은 어소시어티비티 등을 포함한다. 그럼에도 불구하고 실험에서 보인 보정 정확도는 이러한 차이를 어느 정도 상쇄한다는 점을 강조한다. 또한, 현재 제안된 보정은 로컬 특성(노드 평균, 차수 분포 등)에 초점을 맞추며, 전역 특성(예: 그래프 직경) 추정에는 추가 연구가 필요함을 밝힌다. 전체적으로, 이 연구는 BFS 기반 네트워크 탐색이 왜 고도 편향을 보이는지를 수학적으로 명확히 설명하고, 실제 대규모 온라인 소셜 네트워크에 적용 가능한 실용적인 보정 프레임워크를 제공함으로써, 네트워크 과학 및 데이터 수집 분야에 중요한 기여를 한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기