그래프 클러스터링 결과는 그래프 구성에 따라 달라진다
이 논문은 데이터 포인트를 기반으로 만든 다양한 무작위 기하 그래프(k‑NN, r‑graph, 완전 가우시안 그래프)에서 정규화 컷(NCut)과 체거 컷(Cut) 같은 클러스터 품질 지표가 서로 다른 극한값으로 수렴한다는 사실을 밝혀낸다. 따라서 그래프의 종류와 파라미터 선택이 최종 클러스터링 결과에 결정적인 영향을 미치며, 같은 데이터라도 그래프를 다르게 구성하면 전혀 다른 군집 구조가 도출될 수 있음을 이론과 실험을 통해 입증한다.
저자: Markus Maier, Ulrike von Luxburg, Matthias Hein
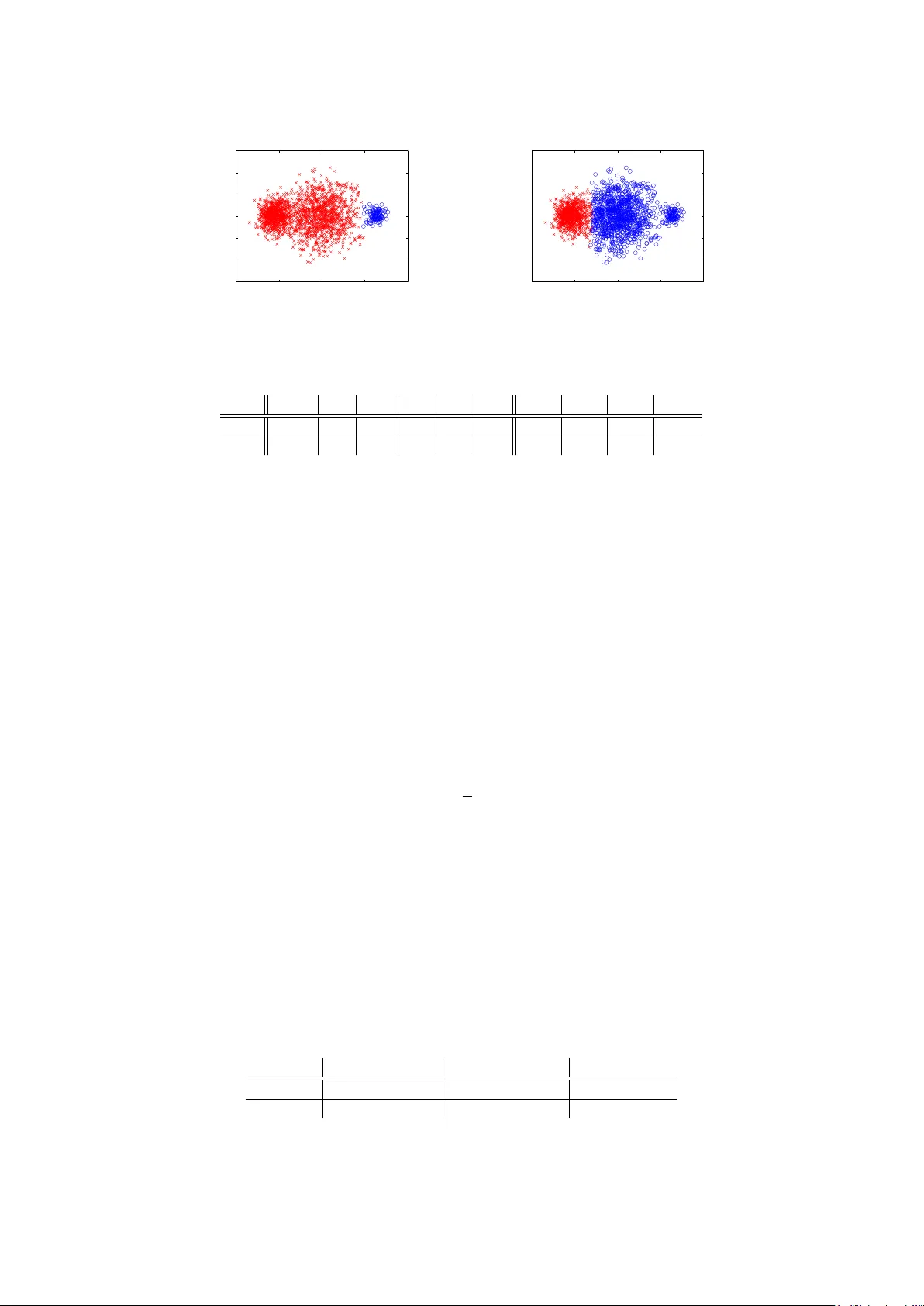
본 논문은 그래프 기반 클러스터링, 특히 스펙트럴 클러스터링에서 데이터 전처리 단계인 그래프 구성 방법이 최종 군집 결과에 미치는 영향을 체계적으로 분석한다. 연구는 크게 네 부분으로 전개된다.
첫 번째 부분에서는 문제 설정과 기존 연구 배경을 소개한다. 데이터 포인트는 ℝᵈ의 확률밀도 p(x)에서 독립적으로 추출되며, 이들을 기반으로 그래프를 만든 뒤 그래프 분할 알고리즘을 적용한다. 기존에는 k‑nearest neighbor(kNN) 그래프, r‑graph, 완전 가우시안 그래프 등 다양한 이웃 그래프가 사용되었지만, 이들 사이의 선택이 클러스터링 품질에 어떤 영향을 주는지는 충분히 밝혀지지 않았다.
두 번째 부분에서는 사용되는 그래프 모델과 가중치 함수를 정의한다. kNN 그래프는 각 점을 k개의 가장 가까운 이웃과 연결하고, 방향성을 고려해 무방향 형태(상호 kNN 혹은 대칭 kNN)로 변환한다. r‑graph는 반경 r 이하의 점들을 연결한다. 완전 가우시안 그래프는 모든 점을 연결하되 가우시안 커널 f(u)= (2πσ²)^{-d/2}exp(-u²/(2σ²)) 로 가중치를 부여한다. 각 그래프에 대해 cut(U,V\U)=∑_{u∈U,v∈V\U}(w(u,v)+w(v,u))와 vol(U)=∑_{u∈U,v∈V}w(u,v)를 정의하고, 정규화 컷(NCut)과 체거 컷(Cut)의 수식을 제시한다.
세 번째 부분이 핵심 이론이다. 저자들은 “고정된 하이퍼플레인 S에 의해 정의된 두 반공간 H⁺, H⁻”을 기준으로, 샘플 크기 n이 무한대로 갈 때 cut과 volume이 각각 s_cutⁿ·cutⁿ → C_utLim, s_volⁿ·volⁿ → V_olLim 로 수렴함을 증명한다. 여기서 스케일링 시퀀스 s_cutⁿ, s_volⁿ는 그래프 종류와 파라미터(k, r, σ)에 따라 달라진다. 구체적으로, 무가중치 r‑graph에서는 s_cutⁿ≈n²r_n^{d+1}·(η_d)^{-1}·(d+1)^{-1}·∫_S p(s)^{1-1/d} ds 로, 가중치가 있는 경우에는 σ와 r_n의 비율에 따라 두 가지 경우(σ_n/r_n→0 혹은 r_n/σ_n→0)로 나뉜다. 완전 가우시안 그래프는 s_cutⁿ≈n²σ_n²·(2π)^{-d/2}·∫_S p(s)² ds 로 수렴한다. 볼륨에 대해서도 유사한 식이 도출되며, kNN 그래프와 r‑graph는 n·r_n^{d}·∫_H p(x)dx 혹은 n·∫_H p(x)²dx 형태, 가우시안 가중치는 σ^{-d}·n·∫_H p(x)²dx 로 나타난다. 이러한 결과를 바탕으로 정규화 컷과 체거 컷의 극한값 N_CutLim, Cheeger_CutLim을 정의하고, 각 그래프에 대해 NCut_n → N_CutLim, CheegerCut_n → Cheeger_CutLim 가 거의 확실히 수렴함을 보인다.
네 번째 부분에서는 이론적 결과가 실제 알고리즘에 미치는 영향을 실험으로 검증한다. 저자들은 2차원 가우시안 혼합 모델을 사용해 “진짜” 클러스터가 존재하는 데이터를 생성하고, 동일한 데이터에 대해 kNN 그래프와 r‑graph를 각각 구축한다. 이후 정규화 스펙트럴 클러스터링을 적용해 얻은 군집 경계를 비교한다. 실험 결과, 두 그래프에서 도출된 군집은 경계 위치가 현저히 다르고, 경우에 따라 하나는 올바른 군집을 찾지만 다른 하나는 크게 잘못된 군집을 만든다. 이는 이론에서 제시된 C_utLim과 V_olLim의 차이가 유한 샘플에서도 충분히 영향을 미친다는 것을 실증한다.
마지막으로 논문은 실용적인 시사점을 제시한다. 비지도 학습에서 그래프 파라미터(k, r, σ)를 어떻게 선택하느냐는 단순히 경험적 규칙이 아니라, 클러스터링 목표 함수 자체의 수학적 극한에 직접적인 영향을 미친다. 따라서 데이터에 맞는 그래프 타입과 파라미터를 선택하기 위한 이론적 가이드라인이 필요하며, 향후 연구에서는 데이터 적응형 파라미터 추정, 다중 그래프 앙상블, 혹은 그래프 선택을 최적화하는 메타-학습 접근법이 유망하다고 제안한다.
요약하면, 이 논문은 그래프 기반 클러스터링에서 그래프 구성 선택이 결과에 결정적인 영향을 미친다는 것을 정량적 이론과 실험을 통해 입증하고, 연구자와 실무자가 그래프 파라미터를 신중히 다루어야 함을 강조한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기