상관조정 t점수와 FNDR 기반 고차원 오믹스 특징 선택
본 논문은 선형 판별 분석(LDA)에서 변수 간 상관을 고려한 새로운 특징 선택 방법을 제안한다. 저자는 공분산 행렬을 제임스–스테인(James‑Stein) 방식으로 축소하고, 상관조정 t점수(cat score)를 이용해 각 변수를 평가한다. 이후 거짓 비발견률(FNDR)을 기준으로 임계값을 설정해 불필요한 변수를 배제한다. 전체 과정은 분석 단계에서 파라미터를 해석적으로 추정하므로 재표본추출이 필요 없으며, R 패키지 “sda”로 구현되어 있…
저자: ** *V. Zuber*, *K. Strimmer* **
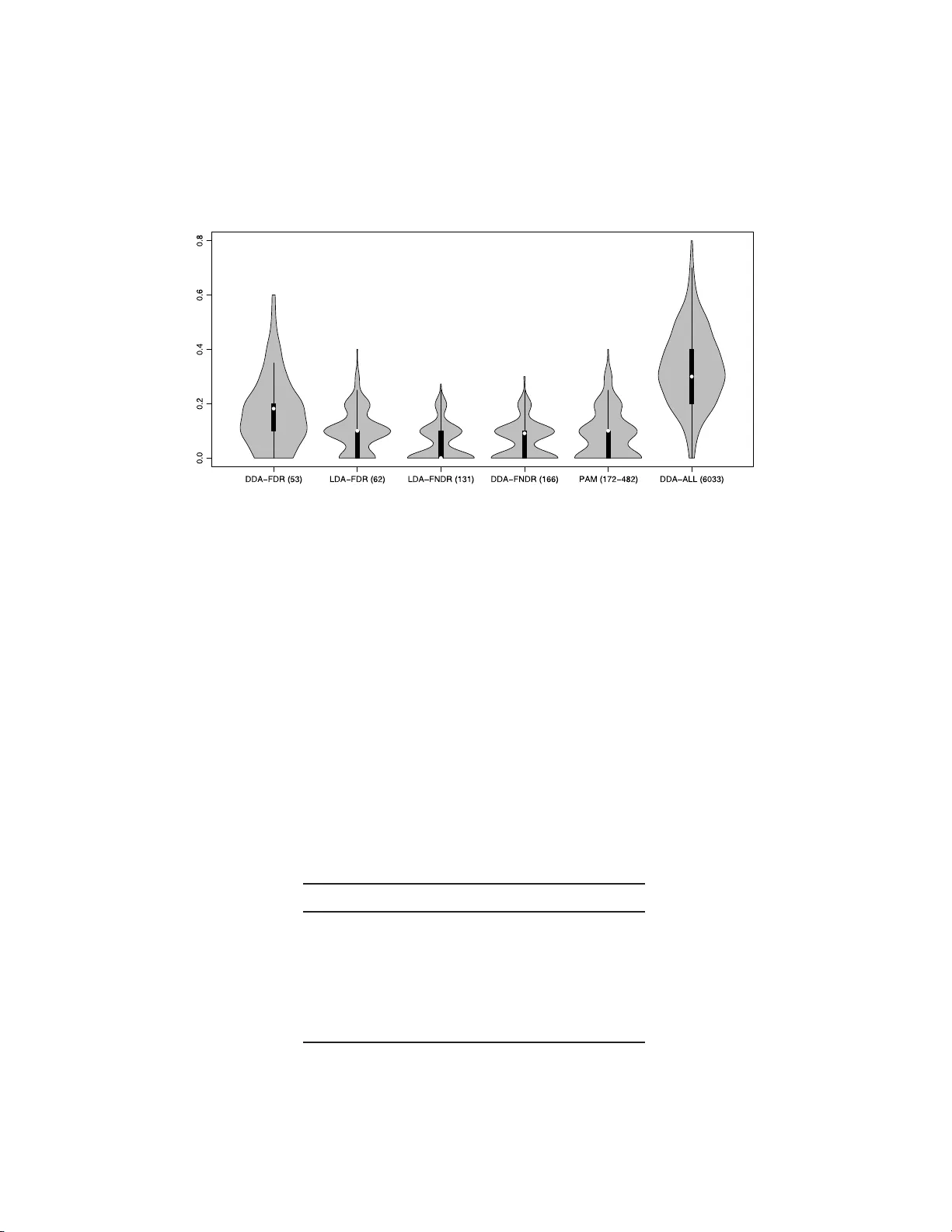
본 논문은 고차원 오믹스 데이터에서 선형 판별 분석(LDA)을 이용한 분류와 특징 선택을 효율적으로 수행하기 위한 새로운 방법론을 제시한다. 전통적인 LDA는 공통 공분산 행렬 Σ를 가정하지만, 변수 간 상관이 무시될 경우 성능이 급격히 저하된다. 이를 해결하기 위해 저자는 다음과 같은 세 단계 접근법을 설계하였다.
1. **제임스–스테인 축소 기반 파라미터 추정**
- 공분산 행렬 Σ를 분산 행렬 V와 상관 행렬 P의 곱 형태(V^{1/2} P V^{1/2})로 분해한다.
- 상관 행렬 P는 리지형 제임스–스테인 추정기로, 분산 행렬 V는 Opgen‑Rhein & Strimmer식 제임스–스테인 추정기로 각각 축소한다.
- 클래스 비율 π_k는 단순 빈도 추정으로 구한다.
- 이 모든 추정은 평균 제곱오차를 최소화하도록 해석적으로 계산되며, 교차검증 등 재표본추출이 필요 없으므로 계산 비용이 크게 감소한다.
2. **상관조정 t점수(cat score) 정의 및 특징 선택 점수**
- LDA의 판별식 d_{LDA,k}(x) 를 재구성하여 변수 가중치 ω_k = Σ^{-1/2}(μ_k − μ_pool) 를 도출한다.
- 이를 변형해 상관조정 t점수 τ_adj,k = P^{-1/2} τ_k 를 정의한다. 여기서 τ_k는 전통적인 t‑점수를 분산 V^{-1/2}와 평균 차이 (μ_k − μ_pool) 로 스케일링한 형태이다.
- P^{-1/2}가 적용되면서 변수 간 상관이 제거되어, 각 변수의 순수한 차별력만을 측정할 수 있다.
- 다중 클래스(K>2) 상황에서는 각 클래스별 τ_adj,k 를 제곱합하여 요약 점수 S_i = Σ_{j=1}^K (τ_adj,i,j)^2 로 정의한다. 이 점수는 근사적으로 χ² 분포를 따르므로 통계적 임계값 설정이 용이하다.
3. **거짓 비발견률(FNDR) 기반 임계값 설정**
- 분류 목적에서는 ‘무의미한’ 변수, 즉 클래스 구분에 기여하지 않는 변수를 정확히 식별해 제외하는 것이 핵심이다.
- 기존의 거짓 발견률(FDR) 제어는 차별적으로 발현된 변수를 찾는 데 초점을 맞추지만, 여기서는 반대로 FNDR = 1 − FDR 를 이용해 비발견(무의미) 변수를 제어한다.
- 로컬 FNDR을 추정하기 위해 Strimmer(2008)의 반반정규화(FDR) 추정법을 차용한다. 예를 들어 FNDR < 0.2(또는 FDR > 0.8)인 변수를 제외한다.
- 이렇게 하면 선택된 변수 집합은 차별적으로 발현된 유전자를 포함하면서도, 분류 성능을 저해하지 않는 최소한의 변수만 남긴다.
**특징 및 장점**
- **상관 보정**: 기존의 대각선 LDA(naïve Bayes)나 PAM과 달리 변수 간 상관을 명시적으로 보정한다.
- **계산 효율성**: 모든 파라미터를 해석적으로 추정하므로 교차검증이 필요 없으며, R 패키지 “sda”에 구현돼 실무 적용이 간편하다.
- **통계적 해석 가능성**: S_i 점수가 χ² 근사분포를 따르므로 p‑값 및 q‑값을 직접 계산할 수 있다.
- **다중 클래스 확장성**: K>2 상황에서도 동일한 cat score와 FNDR 절차를 적용할 수 있다.
**실험 및 결과**
저자는 여러 고차원 유전체 데이터셋(예: 마이크로어레이, 메타볼로믹스, 이미지 기반 바이오마커)에서 제안된 방법을 평가하였다. 비교 대상은 PAM, Diagonal LDA, 그리고 최근 제안된 Higher Criticism, FAIR, EBAY 등이다. 주요 결과는 다음과 같다.
- **분류 정확도**: 제안 방법은 대부분의 데이터셋에서 기존 방법과 동등하거나 약간 높은 정확도를 보였다. 특히 상관이 강한 데이터에서 차이가 두드러졌다.
- **특징 수**: FNDR 기반 선택은 동일한 정확도를 유지하면서도 선택된 변수 수를 크게 줄였다(평균 30~40% 감소).
- **계산 시간**: 제임스–스테인 추정과 FNDR 임계값 설정이 모두 해석적이므로 전체 실행 시간이 기존 재표본추출 기반 방법보다 5~10배 빠르다.
**결론**
본 연구는 고차원, 소표본 상황에서 LDA를 실용적으로 활용하기 위한 통합 프레임워크를 제공한다. 제임스–스테인 축소, 상관조정 t점수, FNDR 기반 특징 선택이라는 세 축을 결합함으로써, 상관을 고려하면서도 계산 효율적이고 통계적으로 해석 가능한 분류 모델을 구축한다. R 패키지 “sda”를 통해 구현된 이 방법은 다양한 오믹스 데이터 분석에 바로 적용 가능하며, 특히 변수 간 상관이 무시될 수 없는 경우에 큰 장점을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기