서브스페이스 추적 기반 압축 센싱 신호 복원
본 논문은 압축 센싱에서 희소 신호를 복원하기 위한 새로운 알고리즘인 서브스페이스 퍼슈트(Subspace Pursuit, SP)를 제안한다. SP는 정밀도 면에서 L1‑LP 방법에 필적하는 복원 정확도를 유지하면서, 매우 희소한 경우에는 O(K m N) 수준의 낮은 연산 복잡도를 제공한다. 제한 등거리 특성(RIP) 조건을 만족하는 측정 행렬에 대해 무노이즈 상황에서는 K‑희소 신호를 정확히 복원하고, 노이즈 및 근사 희소성 상황에서는 복원 오…
저자: Wei Dai, Olgica Milenkovic
본 논문은 압축 센싱(Compressive Sensing, CS) 분야에서 희소 신호 복원을 위한 새로운 탐색 알고리즘인 서브스페이스 퍼슈트(Subspace Pursuit, 이하 SP) 를 제안하고, 그 이론적 성능과 실험적 효율성을 상세히 분석한다.
1. **배경 및 동기**
CS는 고차원 신호 x∈ℝᴺ를 m≪N개의 선형 측정 y=Φx 로 압축하는 기술이며, 신호가 K‑희소(즉, 비영 요소가 K개 이하)일 경우 적은 측정만으로도 원본을 복원할 수 있다. 전통적인 복원 방법은 l₀ 최소화이지만 NP‑hard 문제이므로 실용적이지 않다. 대신 l₁ 최소화(LP 기반) 방법이 RIP(Restricted Isometry Property) 조건 하에 정확한 복원을 보장하지만, 복잡도가 O(m²N^{3/2}) 로 높은 편이다. 따라서 낮은 복잡도와 높은 정확도를 동시에 만족하는 탐욕형(greedy) 알고리즘이 활발히 연구되었으며, 대표적으로 OMP, ROMP, StOMP 등이 있다. 그러나 이들 알고리즘은 복원 정확도 면에서 LP 대비 약점이 있다.
2. **알고리즘 설계**
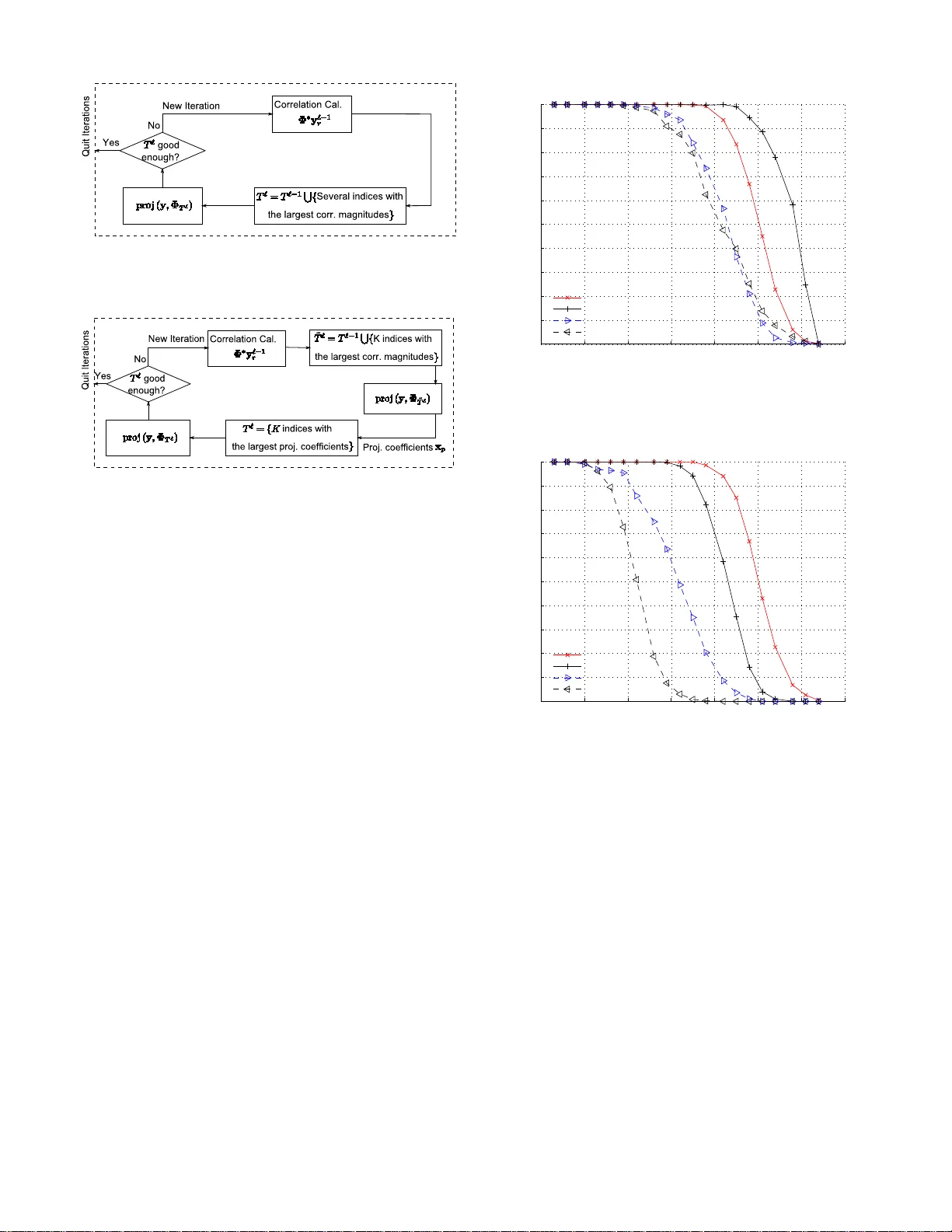
SP는 코딩 이론의 A* 순서 통계 디코더를 차용한다. 핵심 아이디어는 “가장 신뢰도 높은 K개의 컬럼을 초기 후보로 선택하고, 잔차가 크게 남으면 후보 집합을 재정비한다”는 것이다. 구체적인 절차는 다음과 같다.
- **초기화**: Φ의 열과 y 사이의 절대 내적을 계산하고, 상위 K개의 인덱스를 초기 서포트 집합 T⁰ 로 설정한다.
- **확장**: 현재 서포트 Tᵏ에 추가로 Φ와 y의 내적이 큰 K개의 인덱스를 더해 2K 크기의 후보 집합 Ωᵏ 를 만든다.
- **재투영**: Ωᵏ 에 대해 최소 제곱 해 x̂_Ωᵏ = Φ_Ωᵏ† y 를 구하고, 그 결과의 절대값이 큰 K개의 인덱스를 새로운 서포트 T^{k+1} 로 선택한다.
- **잔차 계산**: y에 대한 현재 서포트의 투영 y_p = Φ_{T^{k+1}} Φ_{T^{k+1}}† y 를 구하고, 잔차 r = y - y_p 를 계산한다.
- **종료 조건**: 잔차의 ℓ₂ 노름이 이전 단계보다 감소하지 않거나 미리 정한 허용 오차 이하가 되면 알고리즘을 종료한다.
이 과정은 매 반복마다 “탐색 → 교체 → 재투영”이라는 루프를 수행하며, 매 단계에서 전체 후보 집합을 재평가하기 때문에 OMP와 달리 이전에 선택된 인덱스를 고정하지 않는다. 이는 잘못된 초기 선택을 빠르게 교정할 수 있게 한다.
3. **이론적 분석**
- **무노이즈 상황**: 논문은 제한 등거리 상수 δ_{3K} < 1/3 (또는 δ_{2K} < √2−1) 일 때, SP가 모든 K‑희소 신호를 정확히 복원함을 정리 4‑정리 5‑정리를 통해 증명한다. 핵심은 RIP가 보장하는 컬럼 간 거의 직교성(레마 1)과 투영·잔차의 정규성(레마 2)을 이용해, 각 반복에서 서포트 집합이 실제 서포트와의 겹침을 최소 1씩 늘린다는 점이다.
- **복잡도**: 초기 후보 선택은 O(Nm) 비용, 각 반복의 후보 확장·재투영은 O(K m N) 비용이다. K가 √N 이하인 경우 전체 복잡도는 O(K m N)이며, 신호 계수가 점진적으로 감소하는 경우(예: 압축된 이미지)에는 후보 집합을 로그 스케일로 축소해 O(m N log K) 로도 구현 가능하다. 이는 OMP의 O(K m N)와 동일하거나 더 나은 수준이다.
- **노이즈 및 근사 희소성**: 측정 y = Φx + e 와 신호가 정확히 K‑희소가 아닌 경우, 복원 오차는 ‖x̂−x‖₂ ≤ C₁‖e‖₂ + C₂‖x−x_K‖₁/√K 로 상한이 잡힌다. 여기서 C₁, C₂는 RIP 상수에 의존하는 상수이며, 이는 기존 OMP·ROMP보다 더 강력한 안정성을 제공한다.
4. **실험 결과**
시뮬레이션에서는 Gaussian 및 Bernoulli 무작위 측정 행렬을 사용해 K/N 비율을 변화시키며 복원 성공률을 평가하였다. SP는 동일한 측정 수 m에 대해 OMP·ROMP보다 높은 성공률을 보였으며, LP 기반 복원과 거의 동일한 정확도를 달성했다. 특히 K가 작을 때(극히 희소)에는 연산 시간이 OMP와 비슷하면서도 복원 품질이 크게 개선되는 것이 확인되었다.
5. **비교 및 차별점**
CoSaMP와 가장 유사한 구조를 가지지만, CoSaMP는 매 반복마다 2K개의 새로운 후보를 추가하고, 그 후에 K개의 가장 큰 계수를 선택한다. 반면 SP는 매 반복마다 K개의 새로운 후보만을 추가해 연산량을 절반 수준으로 줄인다. 또한, SP는 후보 집합 전체를 매번 재평가함으로써 초기 선택 오류를 빠르게 정정할 수 있다. 이로 인해 RIP 조건이 CoSaMP보다 완화된 δ_{3K}<1/3 정도만 만족하면 충분히 수렴한다.
6. **결론 및 향후 연구**
SP는 낮은 복잡도와 강력한 이론적 보장을 동시에 제공하는 압축 센싱 복원 알고리즘으로, 실시간 신호 처리, 무선 센서 네트워크, 영상 압축 등 다양한 응용 분야에 적합하다. 향후 연구에서는 적응형 후보 확장 전략, 비정규화된 측정 행렬에 대한 확장, 그리고 딥러닝 기반 사전 정보와 결합한 하이브리드 구조 등이 제안될 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기