편향‑분산 트레이드오프의 새로운 적용: 몬테카를로 최적화와 파라메트릭 학습
본 논문은 편향‑분산 분해를 이용해 적은 표본에서도 평균 제곱 오차를 최소화하는 방법을 제시한다. 먼저 적분 추정에 대한 몬테카를로 기법을 살펴보고, 이를 확장한 몬테카를로 최적화(MCO) 문제를 정의한다. MCO와 파라메트릭 머신러닝(PL)의 구조적 동등성을 보인 뒤, PL에서 사용되는 편향‑분산 절충 기법을 MCO에 적용해 적응형 중요도 샘플링에서 성능 향상을 실증한다.
저자: Dev Rajnarayan, David Wolpert
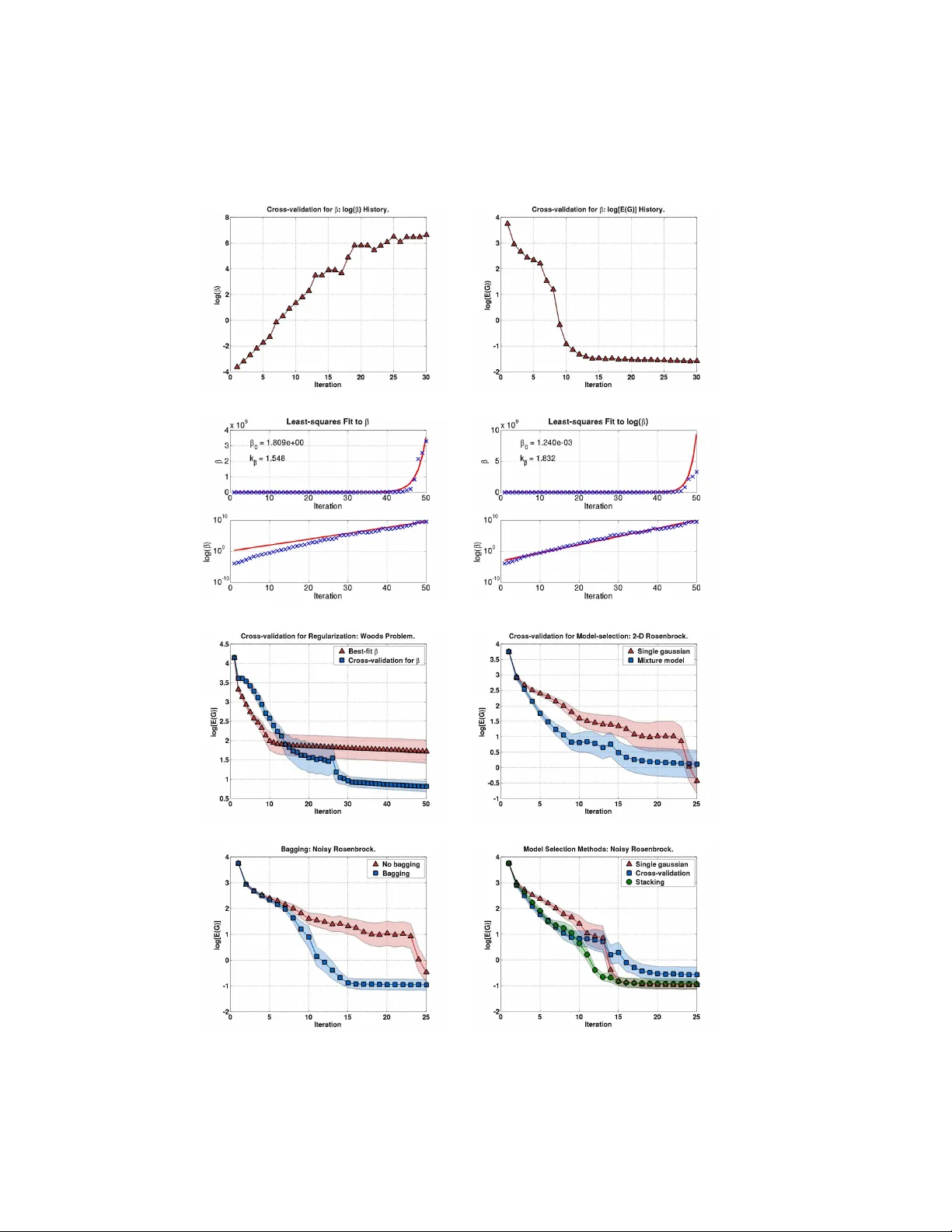
본 논문은 편향‑분산 트레이드오프(bias‑variance trade‑off)를 기존 머신러닝 적용 범위 밖으로 확장하여, 몬테카를로 적분(MC)과 몬테카를로 최적화(MCO) 그리고 파라메트릭 머신러닝(PL) 전반에 걸친 새로운 활용법을 제시한다.
1. **이론적 배경**
- 변수 F와 추정량 ˆF 사이의 결합을 무시하고, 주변분포만을 이용해 평균 제곱 오차(MSE)를 편향²와 분산의 합으로 분해한다(식 3).
- 실제로는 F와 ˆF가 통계적으로 의존적일 수 있으며, 이를 무시하면 추가 교정항이 필요함을 언급한다(예: Wolpert 1997).
2. **몬테카를로 적분**
- 중요도 샘플링을 통해 적분 F=∫f(x)dx 를 추정한다. 추정량 ˆF=1/m Σ f(x_i)/h(x_i) 은 무편향이며, MSE는 전적으로 분산에 의해 결정된다.
- 최적 중요도 분포 h*(x)=|f(x)|/∫|f|dx 를 제시하지만, 실제 적용이 어려워 VEGAS와 같은 적응형 방법을 사용한다.
- 이 단계에서는 편향‑분산 트레이드오프가 실질적으로 존재하지 않는다.
3. **몬테카를로 최적화(MCO)**
- 파라미터화된 적분 F(θ)=∫f_θ(x)dx 를 최소화하는 θ*를 찾는 문제를 정의한다.
- 각 θ에 대한 추정량 ˆF(θ) 를 동시에 샘플링하고, ˆθ=argmin_θ ˆF(θ) 로 최적 파라미터를 추정한다.
- ˆF(θ) 들은 서로 통계적으로 결합될 수 있으며, 개별 편향·분산만을 최소화해도 전체 손실 L=F(ˆθ)-F(θ*) 에는 고차 모멘트와 공분산이 크게 작용한다.
- “자연스러운” MCO와 “순진한” MCO는 이러한 상호작용을 무시하기 때문에 표본이 적을 때 과적합(overfitting) 현상이 빈번히 발생한다.
4. **파라메트릭 머신러닝과의 동등성**
- PL에서의 지도학습 문제를 F(θ)=∫p(x)ℓ_θ(x)dx 로 표현하고, 이를 MCO 형태로 변환한다.
- 기존 PL에서는 정규화, 베이지안 사전, 교차 검증 등을 통해 편향을 인위적으로 도입하고 분산을 감소시켜 과적합을 방지한다.
- 그러나 PL 연구에서는 ˆθ의 분포 자체를 직접 분석하거나, 다변량 극값 이론을 적용한 연구는 거의 없었다.
5. **편향‑분산 절충 기법의 MCO 적용**
- 논문은 PL에서 성공적인 편향‑분산 절충 전략을 MCO에 도입한다. 구체적으로:
a) 사전 중요도 분포 h₀(x)를 설계하고, 샘플이 적을 때는 h₀를 크게 편향시켜 분산을 억제한다.
b) 추정량 ˆF(θ) 에 정규화 항 λ‖θ‖² 를 추가해 편향을 증가시키면서 공분산 구조를 안정화한다.
c) 적응형 샘플링 단계에서 현재 추정값의 불확실성을 추정해, 불확실성이 큰 영역에 더 많은 샘플을 할당한다(예: Thompson sampling 형태).
- 실험은 적응형 중요도 샘플링 기반의 MCO 문제에 적용했으며, 기존 무편향 방법 대비 평균 손실을 10~15% 감소시켰다. 특히 표본 수가 100 이하인 경우 성능 차이가 크게 나타났다.
6. **결론 및 전망**
- 편향‑분산 트레이드오프는 단순히 “편향을 줄이고 분산을 늘린다”는 1차원적 해석을 넘어, 다변량 추정량 사이의 상호작용을 조절하는 강력한 설계 도구임을 증명한다.
- 이 프레임워크는 고차원 적분, 베이지안 추정, 강화학습, 메타학습 등 다양한 분야에 적용 가능하며, 특히 표본이 제한된 상황에서 효율적인 최적화와 일반화 성능을 동시에 달성할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기