카르마카르‑크랩 차분 알고리즘의 심층 분석
본 논문은 무작위 입력에 대해 가장 널리 쓰이는 다항식 시간 휴리스틱인 카르마카르‑크랩(Largest Differencing Method, LDM)의 성능을 비선형 비율 방정식으로 모델링하고, 이를 통해 기대 차이값이 \(E
저자: Stefan Boettcher, Stephan Mertens
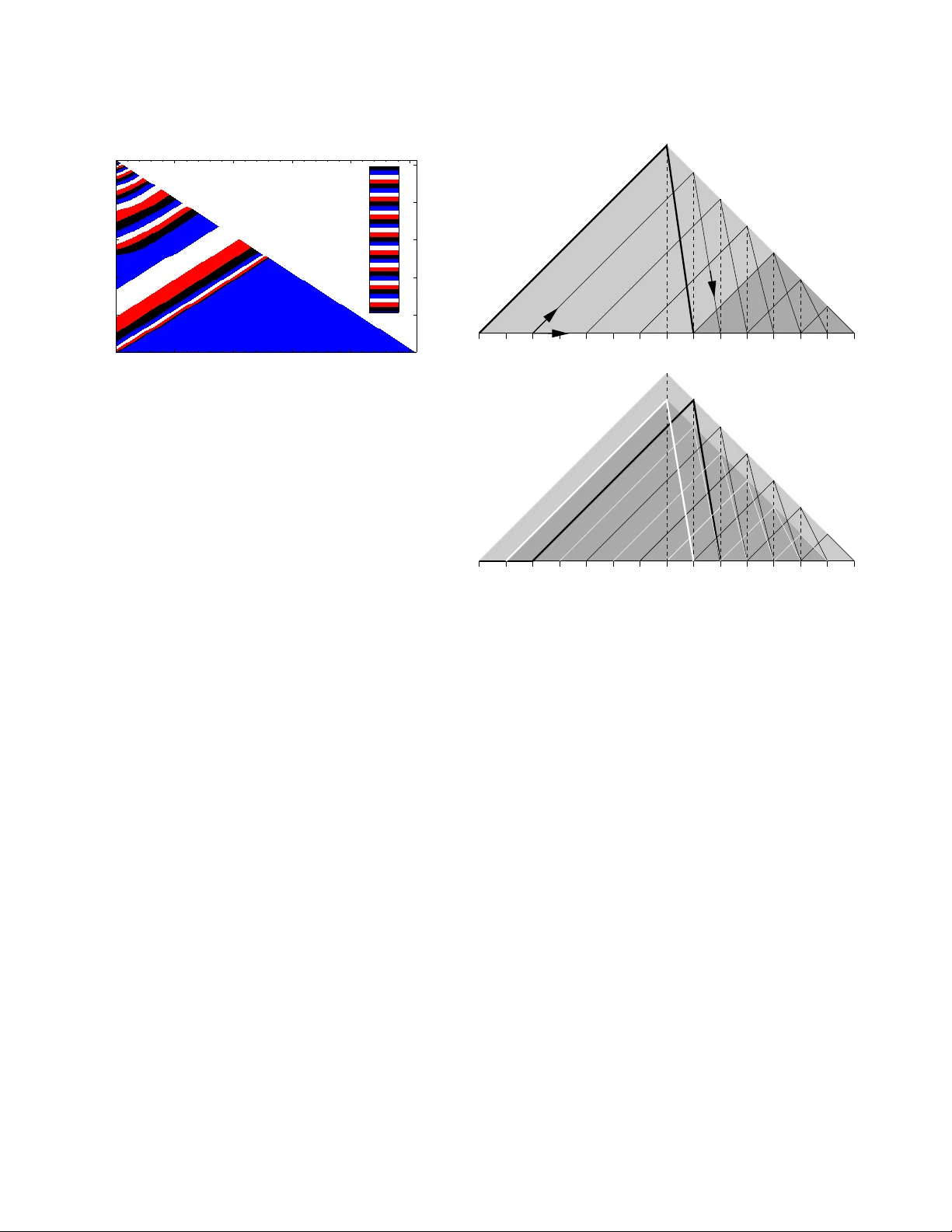
본 연구는 수치 분할 문제(NPP)의 다항식 시간 휴리스틱인 카르마카르‑크랩 차분 알고리즘(LDM)의 평균‑케이스 성능을 정밀하게 분석한다. 먼저, LDM을 “가장 큰 두 수를 차분하고 차를 다시 리스트에 삽입”하는 반복 과정으로 정의하고, 이를 그래프 형태의 트리 구조와 힙 기반 구현으로 시각화한다. 이 과정은 최종 차이가 바로 분할의 불일치(discrepancy)를 의미함을 설명한다.
다음으로, 무작위 입력을 i.i.d. 균등분포 대신 평균 1인 지수분포 변수들의 부분합 \(\{S_k\}\)으로 치환한다. 이는 부분합 비율이 균등 순서통계와 동일함을 이용해, LDM이 입력 분포에 관계없이 동일한 확률적 동작을 보이게 만든다. 이 변환을 통해 알고리즘 전 과정에서 지수분포 형태가 보존되며, 두 가장 큰 변수의 차를 새로운 변수로 만들 때 발생하는 조건부 확률을 Lemma 1로 정확히 계산한다.
Lemma 1에 기반해, λ‑벡터 \((\lambda_1,\dots,\lambda_n)\)가 나타내는 각 지수 파라미터의 전이 확률을 식 (10)‑(13)으로 전개한다. 이 전이는 “새로운 차분값이 리스트에서 k번째 위치에 들어갈 확률”을 구체적으로 제시하고, 전이 후 λ‑벡터의 형태를 명시한다. 이러한 전이 과정을 재귀적으로 적용하면, 최종적으로 두 원소만 남은 상태에서 차분값이 \(\text{EXP}(\lambda_2)\) 분포를 갖게 된다.
전이 규칙을 평균화하면 비선형 비율 방정식(식 21)이 도출된다. 여기서 \(\lambda_t^i\)는 t번째 차분 단계 후 i번째 파라미터를 의미한다. 방정식은 \(\lambda_t^i\)가 이전 단계의 값과 선택된 k에 따라 두 가지 경우 중 하나로 업데이트된다는 점을 반영한다. 수치 해석을 통해 λ‑벡터가 “파동”처럼 전파되는 구조를 발견하고, 이를 Ansatz로 삼아 복잡한 전이식을 단순화한다. 결과적으로 피보나치‑유사 재귀식이 얻어지며, 이는 λ‑벡터의 평균값이 \(n^{-c\ln n}\) 형태로 감소한다는 핵심 스케일링을 증명한다. 여기서 \(c=1/(2\ln2)=0.7213\ldots\)이다.
직관적인 스케일링 추정(식 4‑5)은 차분 횟수가 \(\log_2 n\)임을 이용해 \(E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기