클럼 통계 구성과 정확한 생성함수
이 논문은 단어 집합에서 발생하는 “클럼”(중첩되지 않는 최대 겹침 집합)을 정확히 셈하기 위한 조합론적 방법을 제시한다. 기존 확률론적 접근이 비대칭적인 근사와 대수적 한계에 머물렀던 반면, 저자들은 Régnier‑Szpankowski 언어 분해와 접두코드 이론을 활용해 클럼의 개수, k‑클럼, 클럼이 차지하는 텍스트 길이, 클럼 크기 등에 대한 명시적 생성함수를 도출한다. 특히 Bernoulli 모델과 Markov 모델 모두에 적용 가능하도…
저자: Frederique Bassino, Julien Clement, Julien Fayolle
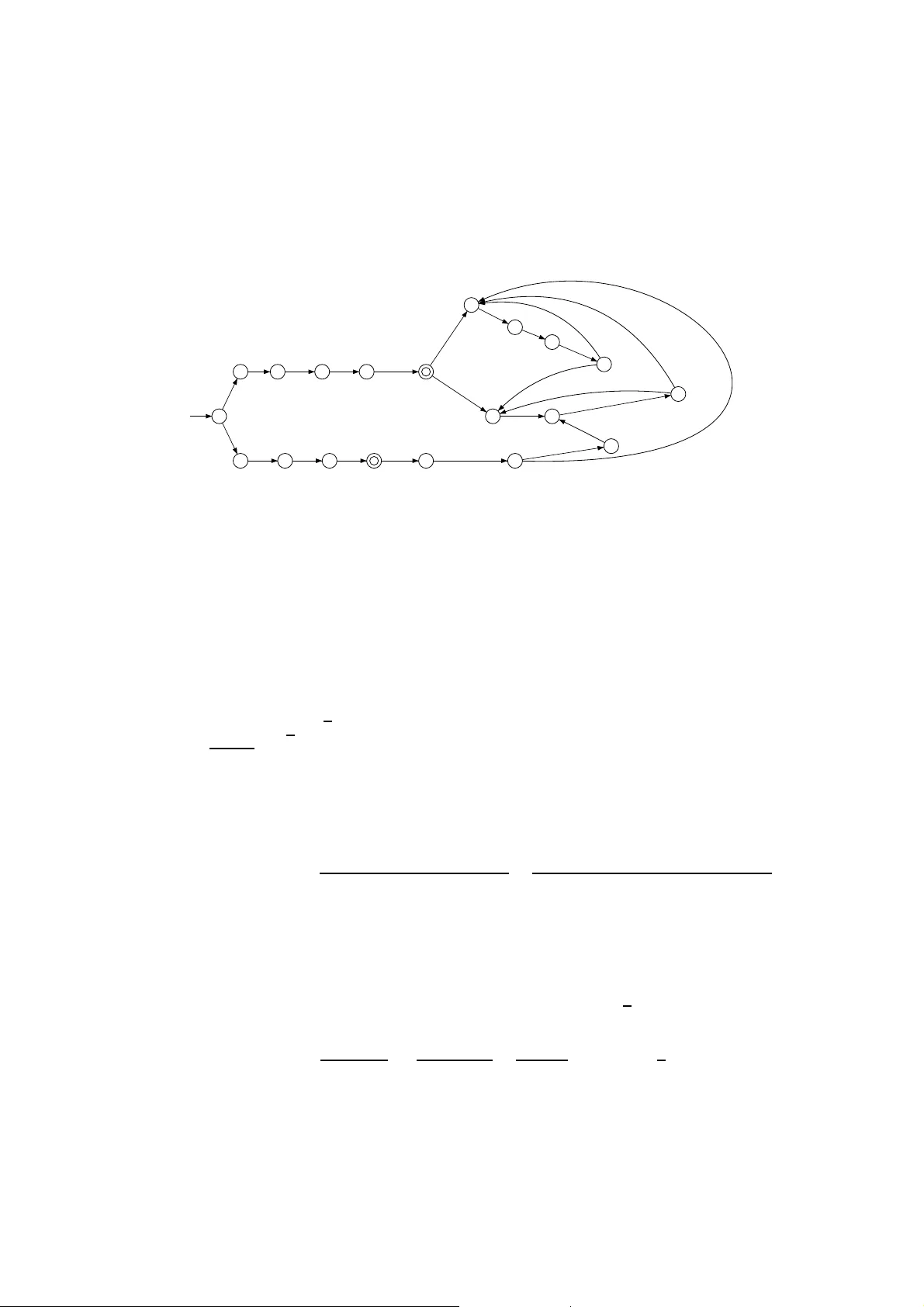
본 논문은 단어 집합 U 에 대해 “클럼”(clump)이라는 새로운 통계적 객체를 정의하고, 이를 정확히 셈하기 위한 조합론적 프레임워크를 구축한다. 클럼은 겹치지 않는 최대 연속 발생 집합으로, 기존 연구에서는 주로 확률론적 근사와 포아송 혹은 복합 포아송 분포를 이용해 대수적 특성을 분석하였다. 그러나 이러한 접근은 텍스트 길이가 충분히 클 때만 근사 정확도가 보장되며, 짧은 시퀀스에서는 오차가 크게 발생한다.
저자들은 먼저 Régnier‑Szpankowski가 제시한 언어 분해 기법을 재해석한다. 단어 w 또는 단어 집합 U 에 대해 “Right”, “Minimal”, “Ultimate”, “Not” 네 종류의 언어를 정의하고, 각각을 생성함수 R(z), M(z), U(z), N(z) 로 표현한다. 이때 R 은 첫 번째 발생 전까지의 문자열, M 은 두 발생 사이의 최소 문자열, U 는 마지막 발생 이후의 문자열, N 은 전혀 발생하지 않는 문자열을 의미한다.
다음으로 자기상관 집합 C (autocorrelation set)을 도입한다. C 은 단어 w 가 자체와 겹칠 수 있는 모든 접미‑접두 관계를 포함한다. C 의 비공백 원소 C◦ 는 유한 언어이며, 이를 기반으로 접두코드 K 를 구성한다. Lemma 1은 K 가 C* (즉, C 의 자유합)를 유일하게 분해한다는 것을 증명한다. 이는 클럼 내부에서 겹치는 발생을 정확히 모델링하기 위한 핵심 단계이다.
그 후, Lemma 2·3을 통해 전체 텍스트를 다음과 같은 구조식으로 분해한다.
텍스트 = N ∪ R·w·(C*)·
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기